你写的是什么功能,不值得一个包,但你想分享?
我会投入一些我的:
destring <- function(x) {
## convert factor to strings
if (is.character(x)) {
as.numeric(x)
} else if (is.factor(x)) {
as.numeric(levels(x))[x]
} else if (is.numeric(x)) {
x
} else {
stop("could not convert to numeric")
}
}
pad0 <- function(x,mx=NULL,fill=0) {
## pad numeric vars to strings of specified size
lx <- nchar(as.character(x))
mx.calc <- max(lx,na.rm=TRUE)
if (!is.null(mx)) {
if (mx<mx.calc) {
stop("number of maxchar is too small")
}
} else {
mx <- mx.calc
}
px <- mx-lx
paste(sapply(px,function(x) paste(rep(fill,x),collapse="")),x,sep="")
}
.eval <- function(evaltext,envir=sys.frame()) {
## evaluate a string as R code
eval(parse(text=evaltext), envir=envir)
}
## trim white space/tabs
## this is marek's version
trim<-function(s) gsub("^[[:space:]]+|[[:space:]]+$","",s)
答案 0 :(得分:27)
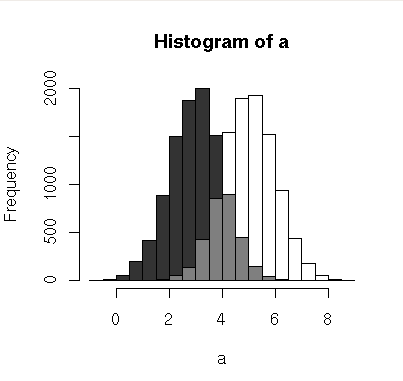
这是一个用伪透明度绘制重叠直方图的函数:
Overlapping Histograms http://chrisamiller.com/images/histOverlap.png
plotOverlappingHist <- function(a, b, colors=c("white","gray20","gray50"),
breaks=NULL, xlim=NULL, ylim=NULL){
ahist=NULL
bhist=NULL
if(!(is.null(breaks))){
ahist=hist(a,breaks=breaks,plot=F)
bhist=hist(b,breaks=breaks,plot=F)
} else {
ahist=hist(a,plot=F)
bhist=hist(b,plot=F)
dist = ahist$breaks[2]-ahist$breaks[1]
breaks = seq(min(ahist$breaks,bhist$breaks),max(ahist$breaks,bhist$breaks),dist)
ahist=hist(a,breaks=breaks,plot=F)
bhist=hist(b,breaks=breaks,plot=F)
}
if(is.null(xlim)){
xlim = c(min(ahist$breaks,bhist$breaks),max(ahist$breaks,bhist$breaks))
}
if(is.null(ylim)){
ylim = c(0,max(ahist$counts,bhist$counts))
}
overlap = ahist
for(i in 1:length(overlap$counts)){
if(ahist$counts[i] > 0 & bhist$counts[i] > 0){
overlap$counts[i] = min(ahist$counts[i],bhist$counts[i])
} else {
overlap$counts[i] = 0
}
}
plot(ahist, xlim=xlim, ylim=ylim, col=colors[1])
plot(bhist, xlim=xlim, ylim=ylim, col=colors[2], add=T)
plot(overlap, xlim=xlim, ylim=ylim, col=colors[3], add=T)
}
如何运行它的示例:
a = rnorm(10000,5)
b = rnorm(10000,3)
plotOverlappingHist(a,b)
更新:FWIW,有一种可能更简单的方法来实现这一点,我已经学会了透明度:
a=rnorm(1000, 3, 1)
b=rnorm(1000, 6, 1)
hist(a, xlim=c(0,10), col="red")
hist(b, add=T, col=rgb(0, 1, 0, 0.5)
答案 1 :(得分:14)
R中fft(快速傅里叶变换)函数的输出处理起来可能有点繁琐。我写了这个plotFFT函数,以便进行FFT的频率与功率曲线。 getFFTFreqs函数(由plotFFT内部使用)返回与每个FFT值关联的频率。
这主要基于http://tolstoy.newcastle.edu.au/R/help/05/08/11236.html
上非常有趣的讨论# Gets the frequencies returned by the FFT function
getFFTFreqs <- function(Nyq.Freq, data)
{
if ((length(data) %% 2) == 1) # Odd number of samples
{
FFTFreqs <- c(seq(0, Nyq.Freq, length.out=(length(data)+1)/2),
seq(-Nyq.Freq, 0, length.out=(length(data)-1)/2))
}
else # Even number
{
FFTFreqs <- c(seq(0, Nyq.Freq, length.out=length(data)/2),
seq(-Nyq.Freq, 0, length.out=length(data)/2))
}
return (FFTFreqs)
}
# FFT plot
# Params:
# x,y -> the data for which we want to plot the FFT
# samplingFreq -> the sampling frequency
# shadeNyq -> if true the region in [0;Nyquist frequency] will be shaded
# showPeriod -> if true the period will be shown on the top
# Returns a list with:
# freq -> the frequencies
# FFT -> the FFT values
# modFFT -> the modulus of the FFT
plotFFT <- function(x, y, samplingFreq, shadeNyq=TRUE, showPeriod = TRUE)
{
Nyq.Freq <- samplingFreq/2
FFTFreqs <- getFFTFreqs(Nyq.Freq, y)
FFT <- fft(y)
modFFT <- Mod(FFT)
FFTdata <- cbind(FFTFreqs, modFFT)
plot(FFTdata[1:nrow(FFTdata)/2,], t="l", pch=20, lwd=2, cex=0.8, main="",
xlab="Frequency (Hz)", ylab="Power")
if (showPeriod == TRUE)
{
# Period axis on top
a <- axis(3, lty=0, labels=FALSE)
axis(3, cex.axis=0.6, labels=format(1/a, digits=2), at=a)
}
if (shadeNyq == TRUE)
{
# Gray out lower frequencies
rect(0, 0, 2/max(x), max(FFTdata[,2])*2, col="gray", density=30)
}
ret <- list("freq"=FFTFreqs, "FFT"=FFT, "modFFT"=modFFT)
return (ret)
}
举个例子,你可以试试这个
# A sum of 3 sine waves + noise
x <- seq(0, 8*pi, 0.01)
sine <- sin(2*pi*5*x) + 0.5 * sin(2*pi*12*x) + 0.1*sin(2*pi*20*x) + 1.5*runif(length(x))
par(mfrow=c(2,1))
plot(x, sine, "l")
res <- plotFFT(x, sine, 100)
或
linearChirp <- function(fr=0.01, k=0.01, len=100, samplingFreq=100)
{
x <- seq(0, len, 1/samplingFreq)
chirp <- sin(2*pi*(fr+k/2*x)*x)
ret <- list("x"=x, "y"=chirp)
return(ret)
}
chirp <- linearChirp(1, .02, 100, 500)
par(mfrow=c(2,1))
plot(chirp, t="l")
res <- plotFFT(chirp$x, chirp$y, 500, xlim=c(0, 4))
哪个给
FFT plot of sine waves http://www.nicolaromano.net/misc/sine.jpg FFT plot of a linear chirp http://www.nicolaromano.net/misc/chirp.jpg
答案 2 :(得分:10)
非常简单,但我经常使用它:
setdiff2 <- function(x,y) {
#returns a list of the elements of x that are not in y
#and the elements of y that are not in x (not the same thing...)
Xdiff = setdiff(x,y)
Ydiff = setdiff(y,x)
list(X_not_in_Y=Xdiff, Y_not_in_X=Ydiff)
}
答案 3 :(得分:6)
# Create a circle with n number of "sides" (kudos to Barry Rowlingson, r-sig-geo).
circle <- function(x = 0, y = 0, r = 100, n = 30){
t <- seq(from = 0, to = 2 * pi, length = n + 1)[-1]
t <- cbind(x = x + r * sin(t), y = y + r * cos(t))
t <- rbind(t, t[1,])
return(t)
}
# To run it, use
plot(circle(x = 0, y = 0, r = 50, n = 100), type = "l")
答案 4 :(得分:5)
我很烦恼打印了很多列的data.frame,我的意思是这是对列的拆分。所以我写了自己的版本:
print.data.frame <- function(x, ...) {
oWidth <- getOption("width")
oMaxPrint <- getOption("max.print")
on.exit(options(width=oWidth, max.print=oMaxPrint))
options(width=10000, max.print=300)
base::print.data.frame(x, ...)
}
答案 5 :(得分:4)
我经常想在回归中使用和比,我通常希望这些术语有意义地命名。所以我写了这个recontrast函数。
recontrast<-function(data,type = "sum"){
data.type <-class(data)
if(data.type == "factor"&!is.ordered(data)&nlevels(data)>1&nlevels(data)<1000){
if(type == "sum"){
contrasts(data)<-contr.sum(levels(data))
colnames(contrasts(data))<-levels(data)[-nlevels(data)]
}else if(type == "treatment"){
contrasts(data)<-contr.treatment(levels(data))
}
}else if(data.type == "data.frame"){
for(i in 1:ncol(data)){
if(is.factor(data[,i]) & !is.ordered(data[,i])&nlevels(data[,i])>1&nlevels(data[,i])<1000){
if(type == "sum"){
contrasts(data[,i])<-contr.sum(levels(data[,i]))
colnames(contrasts(data[,i]))<-levels(data[,i])[- nlevels(data[,i])]
}else if(type == "treatment"){
contrasts(data[,i])<- contr.treatment(levels(data[,i]))
}
}
}
}
return(data)
}
它将整个数据帧和因子作为参数。如果它是一个数据框,它会将无序因子的所有对比度转换为<1000水平的治疗或总和对比。通过总和对比,它有意义地命名列,因此您将在回归输出中包含有意义的标签。
答案 6 :(得分:1)
在最有用的R技巧发布中,我看到了Keving从2009年11月3日发布的一篇文章,其中有关未使用的水平。那里提供了第一个功能。我在第二个函数中迈出了最好的一步,从子集中删除了级别。
drop.levels <- function (dat) {if (is.factor(dat)) dat <- dat[, drop = TRUE] else dat[] <- lapply(dat, function(x) x[, drop = TRUE]); return(dat) ;};
subset.d <- function (...) drop.levels(subset(...)); # function to drop levels of subset
{kind=link}
{kind=link}
{kind=link}