дёәд»Җд№ҲgitдјҡжҺЁйҖҒеҰӮжӯӨеӨҡзҡ„ж•°жҚ®пјҹ
жҲ‘жғізҹҘйҒ“gitеңЁжҺЁеҠЁеҸҳеҢ–ж—¶еҒҡдәҶд»Җд№ҲпјҢд»ҘеҸҠдёәд»Җд№Ҳе®ғдјјд№ҺеҒ¶е°”дјҡжҺЁеҠЁжӣҙеӨҡзҡ„ж•°жҚ®иҖҢдёҚжҳҜжҲ‘жүҖеҒҡзҡ„ж”№еҸҳгҖӮжҲ‘еҜ№дёӨдёӘеўһеҠ дәҶеӨ§зәҰ100иЎҢд»Јз Ғзҡ„ж–Ү件иҝӣиЎҢдәҶдёҖдәӣжӣҙж”№ - дёҚеҲ°2kзҡ„ж–Үжң¬пјҢжҲ‘жғіиұЎгҖӮ
еҪ“жҲ‘е°Ҷж•°жҚ®жҺЁйҖҒеҲ°еҺҹзӮ№ж—¶пјҢgitе°Ҷе…¶иҪ¬жҚўдёәи¶…иҝҮ47mbзҡ„ж•°жҚ®пјҡ
git push -u origin foo
Counting objects: 9195, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6624/6624), done.
Writing objects: 100% (9195/9195), 47.08 MiB | 1.15 MiB/s, done.
Total 9195 (delta 5411), reused 6059 (delta 2357)
remote: Analyzing objects... (9195/9195) (50599 ms)
remote: Storing packfile... done (5560 ms)
remote: Storing index... done (15597 ms)
To <<redacted>>
* [new branch] foo -> foo
Branch foo set up to track remote branch foo from origin.
еҪ“жҲ‘еҢәеҲҶжҲ‘зҡ„жӣҙж”№ж—¶пјҢпјҲorigin / master..HEADпјүеҸӘжҳҫзӨәдәҶдёӨдёӘж–Ү件е’ҢдёҖдёӘжҸҗдәӨгҖӮ 47mbзҡ„ж•°жҚ®жқҘиҮӘе“ӘйҮҢпјҹ
жҲ‘зңӢеҲ°дәҶиҝҷдёӘпјҡWhen I do "git push", what do the statistics mean? (Total, delta, etc.) иҖҢиҝҷпјҡPredict how much data will be pushed in a git push дҪҶйӮЈе№¶жІЎжңүзңҹжӯЈе‘ҠиҜүжҲ‘еҸ‘з”ҹдәҶд»Җд№Ҳ......дёәд»Җд№ҲеҢ…/жҚҶз»‘дјҡеҫҲеӨ§пјҹ
2 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ5)
жҲ‘еҲҡеҲҡж„ҸиҜҶеҲ°йқһеёёзҺ°е®һзҡ„жғ…еҶөдјҡеҜјиҮҙйқһеёёеӨ§зҡ„жҺЁеҠЁгҖӮ
жҺЁйҖҒд»Җд№ҲеҜ№иұЎеҸ‘йҖҒпјҹжңҚеҠЎеҷЁдёҠе°ҡдёҚеӯҳеңЁгҖӮжҲ–иҖ…пјҢиҖҢдёҚжҳҜе®ғзҺ°жңүзҡ„жЈҖжөӢгҖӮе®ғеҰӮдҪ•жЈҖжҹҘеҜ№иұЎзҡ„еӯҳеңЁпјҹеңЁжҺЁйҖҒејҖе§Ӣж—¶пјҢжңҚеҠЎеҷЁеҸ‘йҖҒжңүзҡ„еј•з”ЁпјҲеҲҶж”Ҝе’Ңж ҮзӯҫпјүгҖӮеӣ жӯӨпјҢдҫӢеҰӮпјҢеҰӮжһң他们жңүд»ҘдёӢжҸҗдәӨпјҡ
QTcpSocket* socket = new QTcpSocket();
socket->setSocketDescriptor(socketDesc); // socketDesc is a point of type qintptr
然еҗҺе®ўжҲ·з«Ҝе°ҶиҺ·еҫ—зұ»дјј CLIENT SERVER
(foo) -----------> aaaaa1
|
(origin/master) -> aaaaa0 (master) -> aaaaa0
| |
... ...
зҡ„еҶ…е®№пјҢ并еҸ‘зҺ°е®ғеҝ…йЎ»д»…еҸ‘йҖҒжҸҗдәӨ/refs/heads/master aaaaa0дёӯзҡ„ж–°еҶ…е®№гҖӮ
дҪҶжҳҜпјҢеҰӮжһңжңүдәәе°Ҷд»»дҪ•дёңиҘҝжҺЁеҲ°дәҶиҝңзЁӢжҺҢжҸЎпјҢйӮЈе°ұдёҚеҗҢдәҶпјҡ
aaaaa1жӯӨеӨ„пјҢе®ўжҲ·з«ҜиҺ·еҸ– CLIENT SERVER
(foo) -----------> aaaaa1 (master) --> aaaaa2
| /
(origin/master) -> aaaaa0 aaaaa0
| |
... ...
пјҢдҪҶе®ғеҜ№aaaaa2 дёҖж— жүҖзҹҘпјҢеӣ жӯӨж— жі•жҺЁж–ӯжңҚеҠЎеҷЁдёҠеӯҳеңЁrefs/heads/master aaaaa2гҖӮеӣ жӯӨпјҢеңЁиҝҷдёӘеҸӘжңү2дёӘеҲҶж”Ҝзҡ„з®ҖеҚ•жғ…еҶөдёӢпјҢе°ҶеҸ‘йҖҒж•ҙдёӘеҺҶеҸІи®°еҪ•пјҢиҖҢдёҚжҳҜд»…еўһеҠ еҺҶеҸІи®°еҪ•гҖӮ
иҝҷдёҚеӨӘеҸҜиғҪеҸ‘з”ҹеңЁжҲҗй•ҝпјҢз§ҜжһҒејҖеҸ‘пјҢйЎ№зӣ®пјҢе…¶дёӯжңүж Үзӯҫе’Ңи®ёеӨҡеҲҶж”ҜпјҢе…¶дёӯдёҖдәӣеҸҳеҫ—йҷҲж—§пјҢдёҚдјҡжӣҙж–°гҖӮеӣ жӯӨпјҢз”ЁжҲ·еҸҜиғҪдјҡеҸ‘йҖҒжӣҙеӨҡдҝЎжҒҜпјҢдҪҶе®ғ并没жңүеғҸжӮЁзҡ„жғ…еҶөйӮЈж ·еҸҳеҫ—йӮЈд№ҲеӨ§пјҢ并且没жңүд»»дҪ•жҚҹеӨұгҖӮдҪҶжҳҜеңЁйқһеёёе°Ҹзҡ„еӣўйҳҹдёӯпјҢе®ғеҸҜд»Ҙжӣҙйў‘з№Ғең°еҸ‘з”ҹпјҢиҖҢе·®ејӮе°ҶжҳҜе·ЁеӨ§зҡ„гҖӮ
дёәйҒҝе…Қиҝҷз§Қжғ…еҶөпјҢжӮЁеҸҜд»ҘеңЁжҺЁйҖҒд№ӢеүҚиҝҗиЎҢaaaaa0гҖӮ然еҗҺпјҢеңЁжҲ‘зҡ„зӨәдҫӢдёӯпјҢgit fetchжҸҗдәӨе·ІеӯҳеңЁдәҺе®ўжҲ·з«ҜпјҢиҖҢaaaaa2дјҡзҹҘйҒ“е®ғдёҚеә”еҸ‘йҖҒgit push fooеҸҠжӣҙж—©зҡ„еҺҶеҸІи®°еҪ•гҖӮ
йҳ…иҜ»hereд»ҘдәҶи§ЈеҚҸи®®дёӯзҡ„жҺЁйҖҒе®һзҺ°гҖӮ
PSпјҡжңҖиҝ‘зҡ„git commit graphеҠҹиғҪmight help with itпјҢдҪҶжҲ‘жІЎжңүе°қиҜ•иҝҮгҖӮ
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ3)
В ВеҪ“жҲ‘е°Ҷж•°жҚ®жҺЁйҖҒеҲ°еҺҹзӮ№ж—¶пјҢgitе°Ҷе…¶иҪ¬жҚўдёәи¶…иҝҮ47mbзҡ„ж•°жҚ®..
зңӢиө·жқҘжӮЁзҡ„еӯҳеӮЁеә“еҢ…еҗ«еӨ§йҮҸдәҢиҝӣеҲ¶ж•°жҚ®гҖӮ
йҰ–е…Ҳи®©жҲ‘们зңӢзңӢgit pushдјҡеҒҡд»Җд№Ҳпјҹ
В В
git-push- жӣҙж–°иҝңзЁӢеј•з”Ёд»ҘеҸҠе…іиҒ”еҜ№иұЎ
йӮЈдәӣassociated objectsжҳҜд»Җд№Ҳпјҹ
жҜҸж¬ЎжҸҗдәӨеҗҺпјҢдҪ йғҪдјҡжҠҠgitжү§иЎҢpackдёӘж•°жҚ®еҲ°еҗҚдёәзҡ„ж–Ү件дёӯ
XX.packпјҶamp;пјҶamp; `XX.idx'
жңүе…іеҢ…иЈ…зҡ„еҘҪиҜ»зү©жҳҜhere

git packж–Ү件еҰӮдҪ•пјҹ
В Вжү“еҢ…еӯҳжЎЈж јејҸ
В В В В.packж—ЁеңЁиҮӘеҢ…еҗ«пјҢд»ҘдҫҝеңЁжІЎжңүд»»дҪ•иҝӣдёҖжӯҘдҝЎжҒҜзҡ„жғ…еҶөдёӢи§ЈеҺӢзј©гҖӮ
В В еӣ жӯӨпјҢdeltaжүҖдҫқиө–зҡ„жҜҸдёӘеҜ№иұЎеҝ…йЎ»еӯҳеңЁдәҺеҢ…дёӯгҖӮз”ҹжҲҗеҢ…зҙўеј•ж–Ү件
В В В В.idxпјҢд»Ҙдҫҝеҝ«йҖҹйҡҸжңәи®ҝй—®еҢ…дёӯзҡ„еҜ№иұЎгҖӮе°Ҷзҙўеј•ж–Ү件
.idxе’ҢеҺӢзј©еӯҳжЎЈ.packж”ҫеңЁpackзҡ„{вҖӢвҖӢ{1}}еӯҗзӣ®еҪ•пјҲжҲ–$GIT_OBJECT_DIRECTORYдёҠзҡ„д»»дҪ•зӣ®еҪ•пјүдёӯGitд»ҺеҢ…еӯҳжЎЈдёӯиҜ»еҸ–гҖӮ
еҪ“gitжү“еҢ…дҪ зҡ„ж–Ү件时пјҢе®ғдјҡд»ҘжҷәиғҪзҡ„ж–№ејҸе®ҢжҲҗе®ғпјҢеӣ жӯӨе®ғе°Ҷйқһеёёеҝ«йҖҹжқҘжҸҗеҸ–ж•°жҚ®гҖӮ
дёәдәҶе®һзҺ°иҝҷдёӘgitпјҢдҪҝз”Ёpack-heuristicsеҹәжң¬дёҠеңЁдҪ зҡ„еҢ…дёӯеҜ»жүҫзұ»дјјзҡ„еҶ…е®№йғЁеҲҶ并е°Ҷе®ғ们еӯҳеӮЁдёәеҚ•дёӘеҶ…е®№пјҢиҝҷж„Ҹе‘ізқҖ - еҰӮжһңдҪ жңүи®ёеӨҡзӣёеҗҢзҡ„ж ҮйўҳпјҲдҫӢеҰӮи®ёеҸҜеҚҸи®®пјүж–Ү件пјҢgitе°ҶвҖңжүҫеҲ°вҖқе®ғ并е°ҶеӯҳеӮЁдёҖж¬ЎгҖӮ
зҺ°еңЁпјҢеҢ…еҗ«жӯӨи®ёеҸҜиҜҒзҡ„жүҖжңүж–Ү件йғҪе°ҶеҢ…еҗ«жҢҮй’ҲеҲ°ж ҮеӨҙд»Јз ҒгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢgitдёҚеҝ…еҸҚеӨҚеӯҳеӮЁзӣёеҗҢзҡ„д»Јз ҒпјҢеӣ жӯӨеҢ…еӨ§е°ҸеҫҲе°ҸгҖӮ
иҝҷжҳҜдёәд»Җд№Ҳе®ғдёҚжҳҜдёҖдёӘеҘҪдё»ж„Ҹ并且дёҚе»әи®®еңЁgitдёӯеӯҳеӮЁдәҢиҝӣеҲ¶ж–Ү件зҡ„еҺҹеӣ д№ӢдёҖпјҢеӣ дёәе…·жңүзӣёдјјжҖ§зҡ„еҸҜиғҪжҖ§йқһеёёдҪҺпјҢеӣ жӯӨеҢ…еӨ§е°Ҹе°ҶдёҚжҳҜжңҖдҪізҡ„гҖӮ
Gitд»ҘеҺӢзј©ж јејҸеӯҳеӮЁжӮЁзҡ„ж•°жҚ®д»ҘеҮҸе°‘з©әй—ҙпјҢеӣ жӯӨеҶҚж¬ЎдәҢиҝӣеҲ¶ж–Ү件д№ҹдёҚжҳҜжңҖдҪізҡ„пјҢеӣ дёәеҺӢзј©пјҲеӨ§е°ҸдёәwizeпјүгҖӮ
д»ҘдёӢжҳҜдҪҝз”ЁеҺӢзј©еҺӢзј©зҡ„git blobзӨәдҫӢпјҡ
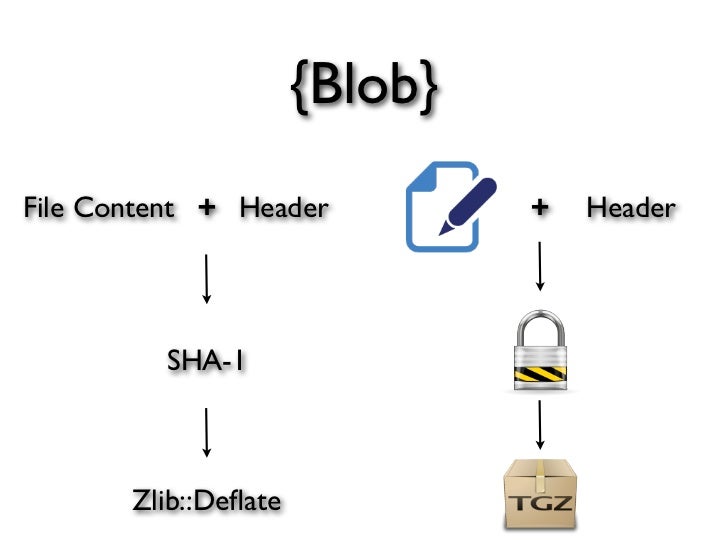
- дёәд»Җд№Ҳиҝҷд№ҲеӨҡи®°еҝҶпјҹ
- дёәд»Җд№ҲвҖңhgжҺЁвҖқжҜ”.hgеӨ§еҫ—еӨҡпјҹ
- дёәд»Җд№ҲжҲ‘зҡ„GitеӯҳеӮЁеә“жҜ”MercurialзүҲжң¬еӨ§еҫ—еӨҡпјҹ
- дёәд»Җд№ҲжҲ‘дҝ®еүӘиҝҮзҡ„git repoд»Қ然еҰӮжӯӨд№ӢеӨ§пјҢжҲ–иҖ…пјҢдёәд»Җд№Ҳжңүиҝҷд№ҲеӨҡжҺЁеҠЁgit push -tagsпјҹ
- дёәд»Җд№Ҳиҝҷд№ҲеӨ§зҡ„е·®ејӮпјҹ
- дёәд»Җд№ҲжҸҗдәӨд»Јз ҒжҜ”иҝҗиЎҢdiffеҝ«еҫ—еӨҡпјҹ
- дёәд»Җд№Ҳgit push origin masterз»ҳеҲ¶ASCIIиүәжңҜпјҹ
- дёәд»Җд№ҲжҲ‘зҡ„GitеӯҳеӮЁеә“жҜ”е·ҘдҪңзӣ®еҪ•еӨ§еҫ—еӨҡпјҹ
- дёәд»Җд№ҲgitдјҡжҺЁйҖҒеҰӮжӯӨеӨҡзҡ„ж•°жҚ®пјҹ
- дёәд»Җд№ҲдёҖж¬Ўиҝҷд№ҲеӨҡ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ