获取特定元素引用的文本
拥有这样的HTML代码段:
<p>Lorem ipsum <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again
and <mark>dolor</mark></p>
我可以使用<mark>选择$("mark")元素。我想得到一个表示mark ed字的字符串列表,左边是5个字符,右边是5个字符,前缀和后缀是[...]字符串。
对于这个例子,它将是:
[
"[...] psum dolor sit [...]",
"[...] met. Lorem ipsu [...]",
"[...] and dolor [...]",
]
目前我是这样的:
var $highlightMarks = $("mark");
var results = [];
for (var i = 0; i < $highlightMarks.length; ++i) {
var $c = $highlightMarks.eq(i);
var text = $c.parent().text().trim().replace(/\n/g, " ");
var indexStart = new RegExp($c.html(), "gim").exec(text).index;
text = "[...] " + text.substring(indexStart - 5, $c.html().length + indexStart + 5) + " [...]";
results.push(text);
}
alert(JSON.stringify(results))<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<p>Lorem ipsum <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</p>
但是当同一段落中的两个单词相同时(在此示例中为dolor情况),这会失败。
不应在数组末尾显示psum dolor sit,而应该是and dolor.。
因此,引用<mark>元素,右侧有一些文本,左侧有一些文本的正确方法是什么?
4 个答案:
答案 0 :(得分:3)
这是一个仅使用正则表达式的两步防弹实现(欢迎反例)。
它最大的优点是独立于标签容器工作(就像<p>...</p>一样提取标记周围的文本)。
var filter = /<(?![/]?mark)[^><]*>/gi;
var regex = /((?:(?!<[/]mark\s*>).){0,5})<mark\s*>([^<]*)<[/]mark\s*>(?=((?:(?!<mark\s*>).){0,5}))/ig;
var subst = "$1 $2 $3";
var tests = ['<p>Lorem ipsum mark> <MARK >dolor</MARK > < mark sitamet. <mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</p>','<P style="margin: 0 15px 15px 0;">um <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</P>','<p>um <mark>dolor</mark> <span>sit</ span> <test amet. <mark>Lorem</mark> <b>i</b>psum again and <mark>dolor</mark>.</p>','<p style="margin: 0 15px 15px 0;" another_tag="123">Lorem ipsum <MARK >dolor</MARK > sit <mark>amet.</mark><mark>Lorem</mark> ipsum again and <mark>dolor</mark>.</P>'];
while(t = tests.pop()) {
document.write('<b>INPUT</b> <xmp>' + t + '</xmp>');
var t = t.replace(filter,'');
document.write('<b>Filtered:</b> <xmp>' + t + '</xmp>');
while ((r = regex.exec(t)) != null) {
pre = r[1]; marked = r[2]; post = r[3];
document.write('<b>Match:</b> "' + pre + ' <mark>' + marked + '</mark> ' + post + '"<hr/>');
}
}
如何运作
-
过滤掉不是
<mark>或</mark>标记的每个标记(根据chrome和firefox接受的内容不区分大小写并放宽空间:正则表达式确实接受变体<mark >或</mark >作为有效标记,但不接受< mark>或</ mark>:/<(?![/]?mark)[^><]*>/gi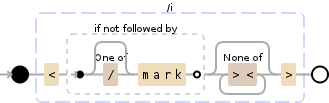
注意:此过滤器正确处理单个字符
'<'和'>'(在其之后/之前有或没有文本)。这与浏览器的不同之处在于开头标记char
<:<someText之后的任何内容,直到下一个有效标记将被删除(打破有效的html标记)。我更喜欢不这样做,并将未关闭的开头'<'视为一个简单的字符。例如:
Some text <notAtag other text <mark>marked</mark>。chrome或firefox会输出Some text marked(marked实际未标记,因为<mark>标记已与<notAtag other text标记一起被过滤掉{1}})。 -
选择标记的文本及其上下文(直到5个字符)
/((?:(?!<[/]mark\s*>).){0,5}) #* 0 to 5 chars that not belongs to '<mark\s*>' # the round brackets save them in group $1 <mark\s*> #* literal string '<mark' followed by # 0 or more whitespace chars then literal '>' ([^<]*) #* 0 or more chars that is not '<' # the round brackets save them in group $2 <[/]mark\s*> #* literal string '</mark' followed by # 0 or more whitespace chars then literal '>' (?=((?:(?!<mark\s*>).){0,5})) #* 0 to 5 chars that not belongs to '</mark\s*>' # lookahead (?=...) used to not consume them # round brackets save them in $3 /ig #* i: Case-insensitive, g: global search
注意:如果是这种情况,正则表达式非常智能,可以从上一个和下一个
<mark>中选择5个字符(例如</mark>12345<mark>,12345将是结束标记的post context和开始标记的pre context。在成瘾中,上下文选择避免选择
<mark>个标签,因此:- 其中有两个相邻的
...</mark><mark>...标记,没有选择任何内容作为后期/上下文; -
</mark>123<mark>:仅选择123作为帖子/上下文。
- 其中有两个相邻的
答案 1 :(得分:1)
您可以使用简单的正则表达式来完成。
[\w\s.]{5} =标记
[^<]+ =匹配标记标记之间的任何内容
var myText = $('p').html();
var reg = new RegExp("([\\w\\s.]{5})<mark>([^<]+)</mark>([\\w\\s]{5})?", "g");
var match = null, matches = [];
while ((match = reg.exec(myText)) !== null) {
var match3 = (typeof match[3] == 'undefined') ? '' : match[3];
matches.push( '[...] ' + match[1] + ' ' + match[2] + ' ' + match3 + '[...]');
}
alert(matches.toString());<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"></script>
<p>Lorem ipsum <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again
and <mark>dolor</mark></p>
匹配数组有4个元素。
首先(匹配[0])一个人拥有所有的比赛。
第二个(匹配[1])包含第一组括号中匹配的所有内容。
第三个(匹配[2])具有与第二组括号匹配的所有内容,即标记标记和
之间第四个(匹配[3])匹配标记标记
后的5个字符答案 2 :(得分:1)
可以使用jquery contents()函数完成。我们可以通过指定索引来选择元素内的文本片段。请查看下面的代码,我已经开发了一个逻辑并实现了它。
$(document).ready(function(){
var marks=$('mark')//get all the mark elements
var j=0;
for(var i=0;i<marks.length;i++){
var markText=marks[i].textContent //get text from each mark element
var content1=$("p").contents().eq(j).text()
//alert("content1"+content1)
content1=content1.substr(content1.length - 5)
j=j+2
var content2=$("p").contents().eq(j).text()
//alert("content2"+content2)
content2=content2.substr(0,5)
var final="[...] "+content1+markText+content2+" [...] "
//alert(final)//you can push this final result into array or something u want
$('body').append("<br>"+final)
}
})<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<p>Lorem ipsum <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again
and <mark>dolor</mark></p>
答案 3 :(得分:0)
我做到了这一点。你可以这样做:
var results = $("p").clone().find("mark").html("1").after(" ").end().html().trim();
results = results.split(" <mark>1</mark> ");
results = results.map(Function.prototype.call, String.prototype.trim);
final = [];
for (var i = 0; i < results.length; i ++) {
if (i != results.length - 1)
final.push(results[i].split(" ")[results[i].split(" ").length - 1]);
if (i != 0)
final.push(results[i].split(" ")[0]);
}
$("pre").text(JSON.stringify(final));
// alert(JSON.stringify(final))<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<p>Lorem ipsum <mark>dolor</mark> sit amet. <mark>Lorem</mark> ipsum again
and <mark>dolor</mark></p>
<pre></pre>
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?