жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–йғЁеҲҶз”өеӯҗйӮ®д»¶ең°еқҖ
жҲ‘жӯЈеңЁе°қиҜ•дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжқҘжҸҗеҸ–вҖң@вҖқз¬ҰеҸ·е’ҢвҖңгҖӮвҖқд№Ӣй—ҙзҡ„з”өеӯҗйӮ®д»¶ең°еқҖзҡ„дёҖйғЁеҲҶгҖӮеӯ—з¬ҰгҖӮиҝҷе°ұжҳҜжҲ‘зӣ®еүҚжӯЈеңЁеҒҡзҡ„дәӢжғ…пјҢдҪҶж— жі•иҺ·еҫ—жӯЈзЎ®зҡ„з»“жһңгҖӮ
company = re.findall('^From:.+@(.*).',line)
з»ҷжҲ‘пјҡ
['@iupui.edu']
жҲ‘жғіж‘Ҷи„ұ.edu
4 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ3)
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ3)
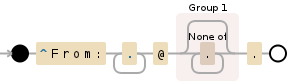
иҰҒеҢ№й…ҚжӯЈеҲҷиЎЁиҫҫејҸдёӯзҡ„ж–Үеӯ—DisposeпјҢжӮЁйңҖиҰҒдҪҝз”Ё.пјҢеӣ жӯӨжӮЁзҡ„д»Јз Ғеә”еҰӮдёӢжүҖзӨәпјҡ
\.и§Ғlive hereгҖӮ
иҜ·жіЁж„ҸпјҢиҝҷе°Ҷе§Ӣз»ҲдёҺеӯ—з¬ҰдёІдёӯcompany = re.findall('^From:.+@(.*)\.',line)
# ^ this position was wrong
зҡ„жңҖеҗҺдёҖж¬ЎеҮәзҺ°еҢ№й…ҚпјҢеӣ дёә.жҳҜиҙӘе©Әзҡ„гҖӮеҰӮжһңжӮЁжғіеҢ№й…Қ first еҮәзҺ°пјҢеҲҷйңҖиҰҒд»ҺжҚ•иҺ·з»„дёӯжҺ’йҷӨд»»дҪ•(.*)пјҡ
. 
жҹҘзңӢdemoгҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ2)
дёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗжҳҜпјҡ
>>> import re
>>> re.findall(".*(?<=\@)(.*?)(?=\.)", "From: atc@moo.com")
['moo']
>>> re.findall(".*(?<=\@)(.*?)(?=\.)", "From: atc@moo-hihihi.com")
['moo-hihihi']
ж— и®әиЎҢзҡ„ејҖеӨҙеҰӮдҪ•пјҢйғҪеҢ№й…Қдё»жңәеҗҚпјҢеҚі greedy гҖӮ
зӯ”жЎҲ 3 :(еҫ—еҲҶпјҡ1)
дҪ еҸҜд»ҘжӢҶеҲҶ并жүҫеҲ°пјҡ
s = " abc.def@ghi.mn I"
s = s.split("@", 1)[-1]
print(s[:s.find(".")])
жҲ–иҖ…еҸӘжҳҜеҲҶиЈӮпјҢеҰӮжһңе®ғдёҚжҖ»жҳҜдёҺдҪ зҡ„еӯ—з¬ҰдёІеҢ№й…Қпјҡ
s = s.split("@", 1)[-1].split(".", 1)[0]
еҰӮжһңжҳҜпјҢйӮЈд№ҲеҸ‘зҺ°е°ҶжҳҜжңҖеҝ«зҡ„пјҡ
i = s.find("@")
s = s[i+1:s.find(".", i)]
- жңүж•Ҳзҡ„з”өеӯҗйӮ®д»¶ең°еқҖжӯЈеҲҷиЎЁ
- жӯЈеҲҷиЎЁиҫҫејҸд»ҺеҸҰдёҖдёӘжӯЈеҲҷиЎЁиҫҫејҸдёӯжҸҗеҸ–з”өеӯҗйӮ®д»¶ең°
- URLжҸҗеҸ–зҡ„жӯЈеҲҷиЎЁиҫҫејҸйғЁеҲҶ
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸд»Һеӯ—з¬ҰдёІдёӯжҸҗеҸ–з”өеӯҗйӮ®д»¶ең°еқҖ
- з”өеӯҗйӮ®д»¶ең°еқҖзҡ„жӯЈеҲҷиЎЁиҫҫејҸ
- жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–йғЁеҲҶеӯ—з¬ҰдёІ
- иҪ»йҮҸзә§з”өеӯҗйӮ®д»¶ең°еқҖжӯЈеҲҷиЎЁиҫҫејҸ
- жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–йғЁеҲҶз”өеӯҗйӮ®д»¶ең°еқҖ
- жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–зү№е®ҡйғЁеҲҶ
- жӯЈеҲҷиЎЁиҫҫејҸз”өеӯҗйӮ®д»¶ең°еқҖPython
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ