似乎无法在Regex中捕获换行符+空格
我知道正则表达式不是网络解析的最佳选择,但我将其用作练习。
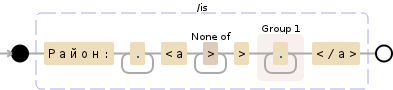
我正在使用Район:[^<>]*\n\s*<[^<>]*>\n\s*<a[^<>]*>([^<>]+)<\/a>
尝试匹配:
Район: </span>
<span class="company__contacts-item-text">
<a class="link" href="/moscow/top/marina-roscha/">Марьина роща</a>
我已经看了一会儿,但我不知道自己做错了什么。如何捕获标签中有换行符和不同URL的内容?
1 个答案:
答案 0 :(得分:1)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?