дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸиҝ”еӣһеҚ•иҜҚдҪҚзҪ®
жҲ‘еңЁjavaдёӯдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸе’ҢеҢ№й…ҚеҷЁж–№жі•иҝ”еӣһеҚ•иҜҚдҪҚзҪ®ж—¶йҒҮеҲ°дәҶйә»зғҰгҖӮ
еҒҮи®ҫжҲ‘жңүдёҖеҸҘиҜқвҖңеҝ«йҖҹзҡ„жЈ•иүІзӢҗзӢёи·іиҝҮдё–з•ҢдёҠжңҖжҮ’зҡ„зӢ—вҖқиҖҢеңЁжҲ‘зҺ°еңЁзҡ„жӯЈеҲҷиЎЁиҫҫејҸдёӯжҲ‘жғіиҰҒиҝ”еӣһдёҖдёӘзү№е®ҡеҚ•иҜҚзҡ„дҪҚзҪ®гҖӮ
еҒҮи®ҫиҫ“е…ҘжҳҜвҖңжЈ•иүІвҖқпјҢд»ҺдёҠйқўзҡ„дҫӢеӯҗдёӯпјҢе®ғеә”иҜҘиҝ”еӣһ3пјҢиҝҷжҳҜеҸҘеӯҗдёӯзҡ„第3дёӘеҚ•иҜҚгҖӮеҰӮжһңе®ғжҳҜвҖңеҝ«йҖҹвҖқпјҢе®ғеә”иҝ”еӣһ2пјҢеҸҘеӯҗдёӯзҡ„第дәҢдёӘеҚ•иҜҚгҖӮеҰӮжһңе®ғжҳҜвҖңдё–з•ҢвҖқйӮЈд№Ҳеә”иҜҘиҝ”еӣһ12.жҲ‘еёҢжңӣжҲ‘е·Із»Ҹз»ҷеҮәдәҶи¶іеӨҹзҡ„дҫӢеӯҗгҖӮ
жҲ‘зҡ„е°қиҜ•жҳҜ
Pattern p= Pattern.compile("(?i)(?<=^|[^A-Z0-9a-z])enemy(?=$|[^A-Z0-9a-z])");
Matcher m = p.matcher("The quickman is an enemy from megaman.");
if(m.find()){
System.out.println(m.start());
System.out.println(m.end());
System.out.println(m.group());
}
дҪҶжҳҜmatcher.startпјҲпјүеҸӘиҝ”еӣһ16зҡ„еӯ—з¬ҰдёІзҙўеј•пјҢиҖҢдёҚжҳҜеҚ•иҜҚзҡ„дҪҚзҪ®гҖӮд»»дҪ•жҸҗзӨәжҲ–её®еҠ©е°ҶдёҚиғңж„ҹжҝҖгҖӮ
1 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ2)
д»ҘдёӢжҳҜеҚ•иҜҚbrownзҡ„зӨәдҫӢпјҡ
\b(?:(brown)|(\S+))\b
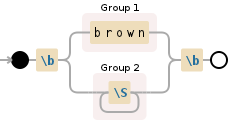
// \b(?:(brown)|(\S+))\b
//
// Options: CaseВ sensitive; ExactВ spacing; DotВ doesnвҖҷtВ matchВ lineВ breaks; ^$В donвҖҷtВ matchВ atВ lineВ breaks; Default line breaks
//
// Assert position at a word boundary (position preceded or followedвҖ”but not bothвҖ”by a Unicode letter, digit, or underscore) В«\bВ»
// Match the regular expression below В«(?:(brown)|(\S+))В»
// Match this alternative (attempting the next alternative only if this one fails) В«(brown)В»
// Match the regex below and capture its match into backreference number 1 В«(brown)В»
// Match the character string вҖңbrownвҖқ literally (case sensitive) В«brownВ»
// Or match this alternative (the entire group fails if this one fails to match) В«(\S+)В»
// Match the regex below and capture its match into backreference number 2 В«(\S+)В»
// Match a single character that is NOT a вҖңwhitespace characterвҖқ (ASCII space, tab, line feed, carriage return, vertical tab, form feed) В«\S+В»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) В«+В»
// Assert position at a word boundary (position preceded or followedвҖ”but not bothвҖ”by a Unicode letter, digit, or underscore) В«\bВ»
жүҫеҲ°иӨҗиүІзҡ„зӨәдҫӢзЁӢеәҸпјҡ
import java.lang.Math;
import java.util.regex.Pattern;
import java.util.regex.Matcher;
import java.util.regex.PatternSyntaxException;
public class HelloWorld
{
public static void main(String[] args)
{
Integer counter = new Integer(0);
String subjectString = "The quick brown fox jumps over the laziest dog in the world";
String testWordString = "brown";
try {
Pattern regex = Pattern.compile("\\b(?:(brown)|(\\S+))\\b");
Matcher regexMatcher = regex.matcher(subjectString);
while (regexMatcher.find()) {
// here increment a count for each word we pass.
counter++;
// matched text: regexMatcher.group()
// match start: regexMatcher.start()
// match end: regexMatcher.end()
System.out.println(regexMatcher.group());
// if the word text `regexMatcher.group()` matches our subject word `brown` exit the loop.
if (testWordString.equals(regexMatcher.group())) {
System.out.println("found the word: " + counter);
break;
}
}
} catch (PatternSyntaxException ex) {
// Syntax error in the regular expression
}
}
}
иҫ“еҮәпјҡ
The
quick
brown
found the word: 3
жіЁж„ҸеҸҜд»Ҙз®ҖеҢ–зӨәдҫӢд»Ҙд»ҺbrownеҲ йҷӨ\b(?:(brown)|(\S+))\bзҡ„жҳҫејҸжөӢиҜ•пјҡ
\b(\S+)\b
дёәпјҡ
brown
дҪҶжҲ‘зҡ„жҖқз»ҙиҝҮзЁӢжҳҜе…Ғи®ёжӮЁдҪҝз”ЁдёҚеҗҢзҡ„жӯЈеҲҷиЎЁиҫҫејҸжҚ•иҺ·з»„жқҘжҢҮзӨәжӮЁжҳҜеҗҰжүҫеҲ°дәҶеҢ№й…ҚпјҢиҖҢдёҚжҳҜжҜҸж¬ЎйғҪдҪҝз”Ёеӯ—з¬ҰдёІжҜ”иҫғapp/design/adminhtml/default/default/template/sales/order/view/items/renderer/default.phtml
гҖӮ
жҲ‘дјҡжҠҠе®ғдҪңдёәй”»зӮјз»ҷдҪ гҖӮ
- йӘҢиҜҒеҚ•иҜҚжҳҜеҗҰеңЁд»»дҪ•дҪҚзҪ®йҮҚеӨҚеҮәзҺ°
- еҰӮжһңд»ҘдёҖдёӘеҚ•иҜҚиҖҢдёҚжҳҜеҸҰдёҖдёӘеҚ•иҜҚејҖеӨҙпјҢеҲҷдҪҝз”ЁRegExиҝ”еӣһеӯ—з¬ҰдёІ
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸеҰӮдҪ•ж №жҚ®е…¶дҪҚзҪ®жӢүдёҖдёӘеҚ•иҜҚ
- strposпјҲпјү;еҚ•иҜҚзҡ„иҝ”еӣһдҪҚзҪ®
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸд»…иҝ”еӣһж•ҙдёӘеҢ№й…ҚеҚ•иҜҚ
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸиҝ”еӣһеҚ•иҜҚдҪҚзҪ®
- з”Ёзү№е®ҡзҡ„еҚ•иҜҚиҝ”еӣһдҪҚзҪ®
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҚ•иҺ·еңЁзү№е®ҡдҪҚзҪ®еҢ…еҗ«еӯ—жҜҚзҡ„еҚ•иҜҚпјҹ
- дҪҝз”ЁPythonжҸҗеҸ–дёҖиЎҢдёӯзү№е®ҡдҪҚзҪ®зҡ„зү№е®ҡеҚ•иҜҚ
- дҪҝз”ЁеҸҳйҮҸиҝӣиЎҢеҢ№й…Қ并иҝ”еӣһе®Ңж•ҙзҡ„еҚ•иҜҚ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ