正则表达式找到最长的文本片段,其中最后一个字母与下一个单词的第一个字母匹配
例如,如果我有像
这样的文字first line of text
badger Royal lemon, night trail
light of. Random string of words
that don't match anymore.
我的结果必须是单词行,其中每个单词的最后一个字符与下一个单词的第一个字符匹配,即使其间有分隔符。在这种情况下:
badger Royal lemon, night trail
light
如果我想使用正则表达式,最简单的方法是什么?
3 个答案:
答案 0 :(得分:2)
匹配每个单词序列的正则表达式为:
(?:\b\w+(\w)\b[\W]*(?=\1))*\1\w+
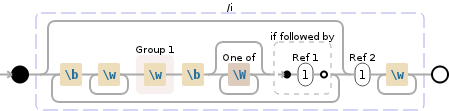
根据您关于允许使用句号,分号,逗号等的规则,您需要调整\W部分。
请注意,这也假设单个字母单词会破坏序列。
然后你可以遍历每个事件并找到最长的:
try {
Regex regexObj = new Regex(@"(?:\b\w+(\w)\b[\W+]*(?=\1))*\1\w+", RegexOptions.IgnoreCase | RegexOptions.Singleline);
Match matchResults = regexObj.Match(subjectString);
while (matchResults.Success) {
// matched text: matchResults.Value
// match start: matchResults.Index
// match length: matchResults.Length
// @todo here test and keep the longest match.
matchResults = matchResults.NextMatch();
}
} catch (ArgumentException ex) {
// Syntax error in the regular expression
}
// (?:\b\w+(\w)\b[\W]*(?=\1))*\1\w+
//
// Options: Case insensitive; Exact spacing; Dot doesn’t match line breaks; ^$ don’t match at line breaks; Numbered capture
//
// Match the regular expression below «(?:\b\w+(\w)\b[\W]*(?=\1))*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Assert position at a word boundary (position preceded or followed—but not both—by a Unicode letter, digit, or underscore) «\b»
// Match a single character that is a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «\w+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
// Match the regex below and capture its match into backreference number 1 «(\w)»
// Match a single character that is a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «\w»
// Assert position at a word boundary (position preceded or followed—but not both—by a Unicode letter, digit, or underscore) «\b»
// Match a single character that is NOT a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «[\W]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Assert that the regex below can be matched, starting at this position (positive lookahead) «(?=\1)»
// Match the same text that was most recently matched by capturing group number 1 (case insensitive; fail if the group did not participate in the match so far) «\1»
// Match the same text that was most recently matched by capturing group number 1 (case insensitive; fail if the group did not participate in the match so far) «\1»
// Match a single character that is a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «\w+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
答案 1 :(得分:0)
我知道这不是正则表达式实现,但......也许有帮助。这是C#中的一个简单实现:
public static string Process (string s)
{
var split = s.Split(new[] { '\n', '\r' }, StringSplitOptions.RemoveEmptyEntries);
if (split.Length < 2)
return null; // impossible to find something if the length is not at least two
string currentString = null;
string nextString = null;
for (var i = 0; i < split.Length - 1; i++)
{
var str = split[i];
if (str.Length == 0) continue;
var lastChar = str[str.Length - 1];
var nextStr = split[i + 1];
if (nextStr.Length == 0) continue;
var nextChar = nextStr[0];
if (lastChar == nextChar)
{
if (currentString == null)
{
currentString = str;
nextString = nextStr.Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries)[0];
}
else
{
if (str.Length > currentString.Length)
{
currentString = str;
nextString = nextStr.Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries)[0];
}
}
}
}
return currentString == null ? null : currentString + "\n" + nextString;
}
答案 2 :(得分:0)
正则表达式无法真正告诉字符串中最长的内容。
但是,使用@DeanTaylor方法,如果全局匹配,您可以存储最长的 基于匹配的字符串长度。
这是他的正则表达式的轻微变化,但它的工作原理相同。
(?:\w*(\w)\W+(?=\1))+\w+
格式化:
(?:
\w*
( \w ) # (1)
\W+
(?= \1 )
)+
\w+
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?