我该如何优化这个正则表达式?
我有这样的文字:
before label bla bla bla aaaa<TAG1>bbbb bla bla bla bla abcd<TAG2>efgh after
和这个正则表达式:
label\W+(?:\w+\W+){1,60}?(?:.){0,}?(\<TAG1\>|\<TAG2\>)(?:.){0,}?\W+(?:\w+\W+){1,60}(?:.){0,}?(\<TAG2\>|\<TAG1\>)(?:.){0,}?
它完成了这项工作,它按预期工作但但似乎并没有真正优化。
这是一项测试:https://regex101.com/r/eS2kS6/1
基本上我必须找到一个标签,在N个单词之后我应该得到<TAG1>或<TAG2>并且在N个单词之后我应该得到<TAG1>或{ {1}}。
注意:
必须将<TAG2>或<TAG1>视为该词的可能“子串”,这一点非常重要。有时它可能是<TAG2>,有时是aaaa<TAG1>bbbb。正如您在示例中所看到的,它适用于两种情况。
1 个答案:
答案 0 :(得分:1)
通常有助于可视化正则表达式:

请注意,(?:.){0,}?是说.*的迂回方式。现在也很容易看出有两个相同的块可以合并,所以我们来解决这个问题:
label\W+(?:(?:\w+\W+){1,60}?.*(\<TAG1\>|\<TAG2\>).*){2}
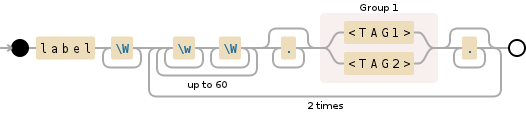
这相当,但更短。从这里开始,问题就在于你究竟想要匹配什么。所有\w和\W对我来说都有些奇怪,特别是与.一起使用时。我通常更喜欢匹配\s而不是\W,因为我通常的意思是&#34;某种空白&#34;,但您需要确定您实际需要的是什么。< / p>
&#34;匹配 - 一到六十个单词 - 而不是单词 - 后跟任何&#34;您正在使用的模式((?:\w+\W+){1,60}?.*)可能不是您想要的模式 - 例如它匹配a$<TAG,但不匹配a<TAG。如果您想允许一个或多个单词,请尝试(?:\s*\w+)+。这匹配零或多个空格,后跟一个或多个字符,一次或多次。如果您希望将其限制为60,则可以使用+替换最终的{1,60}(但您的说明中不清楚60来自何处label\s+(?:(?:\w+\s*)+(\<TAG1\>|\<TAG2\>)\w*){2}
- 你需要吗?)。
所以我们现在就在这里:
after 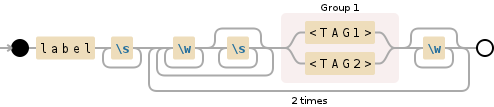
这与您之前的模式完全相同 - 它与您的示例字符串中的.*不匹配(从您的描述中不清楚)是否应该)。如果您想在第二个标记之后保持匹配,只需在末尾添加N。
所有这一切,它看起来很像你试图解析一个复杂的语法(即non-regular language),那就是rife with peril。如果您发现自己编写并重写正则表达式以尝试捕获所需的数据,则可能需要升级到正确的上下文解析器。
特别是,正则表达式和我的调整都没有强制N每次都相同。您的说明听起来似乎只想匹配第一个标记之前有N个字词的字符串,以及它与第二个标记之间的$("html, body").animate({ scrollTop: $(document).height() }, "slow");
字。使用正则表达式可以实现这种匹配,但它肯定不会干净。如果这是一项要求,正则表达式可能不是正确的工具。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?