如何用R'正则表达式替换方括号和大括号?
由于pandoc-citeproc和乳胶之间的转换,我想替换这个
\cite{Fotheringham1981}
用这个
x <- c("[@Fotheringham1981]", "df[1,2]")
x1 <- gsub("\\[@", "\\\\cite{", x)
x2 <- gsub("\\]", "\\}", x1)
x2[1] # good
## [1] "\\cite{Fotheringham1981}"
x2[2] # bad
## [1] "df[1,2}"
以下可重复的示例说明了单独处理每个支架的问题。
old_rmd <- "$p = \alpha e^{\beta d}$ [@Wilson1971] and $p = \alpha d^{\beta}$
[@Fotheringham1981]."
new_rmd1 <- gsub("\\[@([^\\]]*)\\]", "\\\\cite{\\1}", old_rmd, perl = T)
new_rmd2 <- gsub("\\[@([^]]*)]", "\\\\cite{\\1}", old_rmd)
new_rmd1
## "$p = \alpha e^{\beta d}$ \\cite{Wilson1971} and $p = \alpha d^{\beta}$\n \\cite{Fotheringham1981}."
new_rmd2
## [1] "$p = \alpha e^{\beta d}$ \\cite{Wilson1971} and $p = \alpha d^{\beta}$\n\\cite{Fotheringham1981}."
针对C#看到类似的问题solved,但没有使用R&#39的perre正则表达式 - 任何想法?
编辑:
它应该能够处理长文档,例如
if3 个答案:
答案 0 :(得分:3)
您可以使用
gsub("\\[@([^]]*)]", "\\\\cite{\\1}", x)
请参阅IDEONE demo
正则表达式细分:
-
\\[@- 文字[@符号序列 -
([^]]*)- 一个匹配0个或多个符号但只有]的捕获组1(请注意,如果]出现在字符类的开头,则不会需要逃避) -
]- 文字]符号
您不需要使用perl=T,因为字符类中的]不会被转义。否则,它将需要使用该选项。
另外,我相信我们应该逃避必须逃脱的事情。如果有办法避免backslash hell,我们应该。因此,您甚至可以使用
gsub("[[]@([^]]*)]", "\\\\cite{\\1}", x)
为什么基于TRE的正则表达式比PCRE更好:
在R 2.10.0及更高版本中,默认的正则表达式引擎是Ville Laurikari的TRE引擎[source]的修改版本。花费在匹配上的library's author states随着输入文本长度的增加而线性增长,而内存需求几乎是恒定的(几十千字节)。 TRE也是said在所使用的正则表达式匹配算法的长度中使用可预测和适度的内存消耗以及二次最坏情况时间。这就是为什么在处理更大的文档时,最好依赖TRE而不是PCRE正则表达式。
答案 1 :(得分:2)
您需要使用捕获组。
x <- c("[@Fotheringham1981]", "df[1,2]")
gsub("\\[@([^\\]]*)\\]", "\\\\cite{\\1}", x, perl=T)
# [1] "\\cite{Fotheringham1981}" "df[1,2]"
或
gsub("\\[@(.*?)\\]", "\\\\cite{\\1}", x)
# [1] "\\cite{Fotheringham1981}" "df[1,2]"
答案 2 :(得分:1)
匹配[@,然后设置一个捕获组,即(...)中的所有内容,然后.*?匹配最短的字符串,直到]:
gsub("\\[(@.*?)\\]", "\\\\cite{\\1}", x)
## [1] "\\cite{@Fotheringham1981}" "df[1,2]"
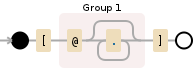
这是正则表达式的铁路图:
\[(@.*?)\]
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?