为什么/^[a-zA-Z0-9]+@[a-zA-Z0-9]\.(com)|(edu)|(org)$/i无法正常工作
我有这个正则表达式用于电子邮件验证(假设只有x@y.com,abc@defghi.org,some@anotherhting.edu有效)
/^[a-zA-Z0-9]+@[a-zA-Z0-9]\.(com)|(edu)|(org)$/i
但 @ abc.edu 和 abc@xyz.eduorg 对于上面的正则表达式都有效。谁能解释为什么会这样?
我的方法:
-
@
之前至少应有一个字符或数字
-
然后有@
- @和之前应该至少有一个字符或数字。
- 字符串应以edu,com或org结尾。
5 个答案:
答案 0 :(得分:3)
试试这个
/^[a-zA-Z0-9]+@[a-zA-Z0-9]+\.(com|edu|org)$/i
它应该变得清晰 - 你需要对这些替代品进行分组,否则你可以匹配任何具有' edu'在其中,或以org结尾的任何字符串。换句话说,你的版本匹配任何这些模式
-
^[a-zA-Z0-9]+@[a-zA-Z0-9]\.(com) -
(edu) -
(org)$
值得指出的是,原始海报正在使用它作为正则表达式学习练习。对于实际生产使用来说,这将是一个可怕的正则表达式!这是一个棘手的问题 - 请更深入地了解Using a regular expression to validate an email address。
答案 1 :(得分:3)
您的分组括号不正确:
/^[a-zA-Z0-9]+@[a-zA-Z0-9]+\.(com|edu|org)$/i
也可以在使用i修饰符时使用一个案例:
/^[a-z0-9]+@[a-z0-9]+\.(com|edu|org)$/i
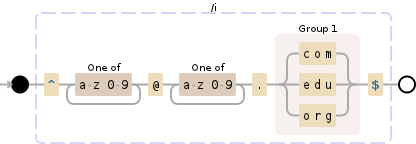
N.B。你还错过了第二组中的+,我认为这只是一个错字......
答案 2 :(得分:3)
您所写的内容相当于匹配以下内容:
开始[a-zA-Z0-9] + @ [a-zA-Z0-9] .com
包含edu
或以org结束
你在寻找的是:
/^[a-z0-9]+@[a-z0-9]+\.(com|edu|org)$/i
答案 3 :(得分:2)
你的正则表达式看起来不错。
我猜你正在寻找使用find函数而不是匹配函数
如果没有指定你使用的东西,它有点困难,但在Python中你会写
import re
pattern = re.compile ('^[a-zA-Z0-9]+@[a-zA-Z0-9]\.(com)|(edu)|(org)$')
re.match('@abc.edu') # fails, use this to validate an input
re.search('@abc.edu') # matches, finds the edu
答案 4 :(得分:-2)
尝试使用它: [A-ZA-Z0-9] + @ [A-ZA-Z0-9] +(COM | EDU |单位)。+ $
如果你想捕捉(com | edu | org)的任何组合,你会忘记+修饰符
更新:因为我看到第二个[a-zA-Z0-9]你也错过了+
相关问题
- ^ [A-Za-Z] [A-Za-z0-9] *正则表达式?
- ^ [A-Za-z] [A-Za-z0-9] * $正则表达式?
- Java - 传递为[a-zA-z0-9] *的未知字符?
- ^ a-zA-Z0-9除了空格?
- RewriteRule([A-Za-z0-9 - ] +) - 至404
- 正则表达式(#,?,:)[a-zA-Z0-9] * _ *是什么意思?
- 正则表达式 - val.replace(/ ^ [^ a-zA-Z0-9] * | [^ a-zA-Z0-9] * $ / g,"'');
- 正则表达式[a-zA-Z0-9]不起作用?
- 为什么/^[a-zA-Z0-9]+@[a-zA-Z0-9]\.(com)|(edu)|(org)$/i无法正常工作
- REGex - 怎么来的([ÆØÅæøåa-zA-Z0-9 .-] +)$有效但是([a-zA-Z0-9.-ÆØÅæøå] +)$不行?
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?