匹配此字符串的正则表达式是什么?
考虑以下句子:
苹果是2公斤 苹果香蕉芒果是2千克 苹果苹果是6公斤
香蕉香蕉香蕉是6kg
鉴于“苹果”,“香蕉”和“芒果”是唯一的果实,提取出现在句子开头的水果名称的正则表达式是什么?
我写了这个正则表达式(https://regex101.com/r/fY8bK1/1):
^(apple|mango|banana) is (\d+)kg$
但这仅在句子中有单个水果时匹配。
如何提取所有水果名称?
所有4个句子的预期输出应为:
apple,2
苹果香蕉芒果,2
苹果苹果,6
香蕉香蕉香蕉,6
4 个答案:
答案 0 :(得分:4)
您可以使用这样的分组:
^((?:apple|mango|banana)(?:\s+(?:apple|mango|banana))*) is (\d+)kg$
请参阅regex demo
(?:...)是捕获((...))组内的非捕获组,以免在输出中造成混乱。
((?:apple|mango|banana)(?:\s+(?:apple|mango|banana))*)组匹配:
-
(?:apple|mango|banana)- 使用替换|运算符分隔的备用列表中的任何值。如果您打算仅匹配整个单词,请将\b放在子模式的两端。 -
(?:\s+(?:apple|mango|banana))*匹配0个或更多个序列...-
\s+- 一个或多个空格 -
(?:apple|mango|banana)- 任何替代方案。
-
段:
var re = /^((?:apple|mango|banana)(?:\s+(?:apple|mango|banana))*) is (\d+)kg$/gm;
var str = 'apple is 2kg\napple banana mango is 2kg\napple apple apple is 6kg\nbanana banana banana is 6kg';
var m;
while ((m = re.exec(str)) !== null) {
document.write(m[1] + "," + m[2] + "<br/>");
}
document.write("<b>appleapple is 2kg</b> matched: " +
/^((?:apple|mango|banana)(?:\s+(?:apple|mango|banana))*) is (\d+)kg$/.test("appleapple is 2kg"));
答案 1 :(得分:2)
试试这个
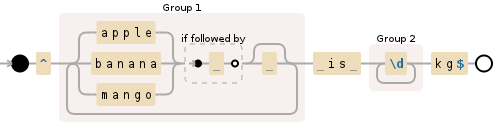
var re = /^((?:(?:apple|banana|mango)(?= ) ?)+) is (\d+)kg$/gm;
re.exec('apple banana mango is 2kg');
// ["apple banana mango is 2kg", "apple banana mango", "2"]
这与其他答案的不同之处是什么?水果选项之后的(?= ) ?强制空格作为下一个字符,但除非有更多水果(或者你将 分开两倍),否则不会捕获它。
在while循环中使用它可以从多行字符串中获取所有结果。
这里的gm标志允许此 RegExp 使用re.exec多次应用于同一 String ,其中新行匹配{{1 }}。但是,$^标记会导致g的行为不同。
如果您希望对每个字符串进行独立测试,可以继续使用str.match或删除这些标记并使用re.exec代替
str.match答案 2 :(得分:1)
/^(((apple|mango|banana)\s*)+) is (\d+)kg$/$1,$4/gm
DEMO:https://regex101.com/r/sA4aW7/2
所以你从这里开始,其中一个:
(apple|mango|banana)
让我们把最终的空白分开重复:
(apple|mango|banana)\s*
和所有(至少一个)重复:
((apple|mango|banana)\s*)+
需要添加一个额外的组,因为您希望单个组捕获该批次:
(((apple|mango|banana)\s*)+)
添加此点,$1(最外面的组)将包含“香蕉香蕉香蕉......”;第四个你的体重。添加您自己的?:以避免捕获内部群组if you like。
答案 3 :(得分:0)
^((?:apple|mango|banana| )+) is (\d+)kg\s?$/gmi
<强>样本
https://regex101.com/r/dO1rR7/1
<强>解释
^((?:apple|mango|banana| )+) is (\d+)kg\s?$/gmi
^ assert position at start of a line
1st Capturing group ((?:apple|mango|banana| )+)
(?:apple|mango|banana| )+ Non-capturing group
Quantifier: + Between one and unlimited times, as many times as possible, giving back as needed [greedy]
1st Alternative: apple
apple matches the characters apple literally (case sensitive)
2nd Alternative: mango
mango matches the characters mango literally (case sensitive)
3rd Alternative: banana
banana matches the characters banana literally (case sensitive)
4th Alternative:
matches the character literally
is matches the characters is literally (case sensitive)
2nd Capturing group (\d+)
\d+ match a digit [0-9]
Quantifier: + Between one and unlimited times, as many times as possible, giving back as needed [greedy]
kg matches the characters kg literally (case sensitive)
\s? match any white space character [\r\n\t\f ]
Quantifier: ? Between zero and one time, as many times as possible, giving back as needed [greedy]
$ assert position at end of a line
g modifier: global. All matches (don't return on first match)
m modifier: multi-line. Causes ^ and $ to match the begin/end of each line (not only begin/end of string)
i modifier: insensitive. Case insensitive match (ignores case of [a-zA-Z])
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?