Python - 正则表达式 - 匹配除了另一种模式
目标:返回与所有开头序列匹配但不包括大小序列的分组。
## List of strings and desired result
strs = [
'151002 - Some name', ## ('151002 - ', 'Some name')
'Another name here', ## ('', 'Another name here')
'13-10-07_300x250_NoName', ## ('13-10-07_', '300x250_NoName')
'728x90 - nice name' ## ('', '728x90 - nice name')
]
尝试模式
## This pattern is close
##
pat = '''
^ ## From start of string
( ## Group 1
[0-9\- ._/]* ## Any number or divider
(?! ## Negative Lookahead
(?:\b|[\- ._/\|]) ## Beginning of word or divider
\d{1,3} ## Size start
(?:x|X) ## big or small 'x'
\d{1,3} ## Size end
)
)
( ## Group 2
.* ## Everthing else
)
'''
## Matching
[re.compile(pat, re.VERBOSE).match(s).groups() for s in strs]
尝试的模式结果
[
('151002 - ', 'Some name'), ## Good
('', 'Another name here'), ## Good
('13-10-07_300', 'x250_NoName'), ## Error
('728', 'x90 - nice name') ## Error
]
2 个答案:
答案 0 :(得分:3)
我认为这可能会给你你想要的东西:
[re.match(r"^([^x]+[\-_]\s?)?(.*$)", s).groups() for s in strs]
正则表达式的说明:从字符串的开头开始,查找一个或多个不是x的字符,后面跟一个连字符或下划线,后跟一个空格。这是第一组,可以是零或一组。第二组是其他一切。
<强> 编辑:
假设您的字符串在数字中可以包含字母x以外的字符,您可以将代码修改为:
[re.match(r"^([^a-zA-Z]+[\-_]\s?)?(.*$)", s).groups() for s in strs]
答案 1 :(得分:1)
我认为你误解了前瞻的使用。这种模式应该有效
((?:(?!\d{1,3}x\d{1,3})[0-9\- ._/])*)(.*)
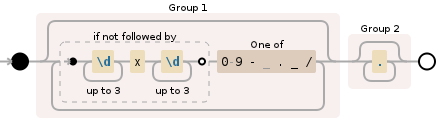
如果你想要一个解释,因为我知道这是一个恶心的正则表达式,只要问:)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?