preg_match_all和foreach只替换最后一场比赛
我有以下代码,它应该使纯文本链接可以点击。但是,如果有多个链接,则只替换最后一个链接。
代码:
$nc = preg_match_all('#<pre[\s\S]*</pre>#U', $postbits, $matches_code);
foreach($matches_code[0] AS $match_code)
{
$match = null;
$matches = null;
$url_regex = '#https?://(\w*:\w*@)?[-\w.]+(:\d+)?(/([\w/_.]*(\?\S+)?)?)?[^<\.,:;"\'\s]+#';
$n = preg_match_all($url_regex, $match_code, $matches);
foreach($matches[0] AS $match)
{
$html_url = '<a href="' . $match . '" target="_blank">' . $match . '</a>';
$match_string = str_replace($match, $html_url, $match_code);
}
$postbits = str_replace($match_code, $match_string, $postbits);
}
结果:
http://www.google.com
http://www.yahoo.com
http://www.microsoft.com/ <-- only this one is clickable
预期结果:
我的错误在哪里?
1 个答案:
答案 0 :(得分:0)
如果有多个链接,则只替换最后一个
我的错误在哪里?
实际上,它取代了所有3个链接,但每次都会替换原始字符串。
foreach($matches[0] AS $match)
{
$html_url = '<a href="' . $match . '" target="_blank">' . $match . '</a>';
$match_string = str_replace($match, $html_url, $match_code);
}
循环执行3次,每次取代$match_code中的1个链接,并将结果分配给$match_string。在第一次迭代中,$match_string会为可点击 google.com分配结果。在第二次迭代中,$match_string被分配了可点击的 yahoo.com。但是,您刚刚替换了原始字符串,因此google.com现在不是可点击。这就是为什么你只得到你的最后一个链接的原因。
您可能还需要在代码中更正一些事项:
- 正则表达式
#<pre[\s\S]*</pre>#U最好构造为#<pre.*</pre>#Us。类[\s\S]*通常用于JavaScript,其中没有s标记,以允许点匹配换行符。 - 我不知道您为什么要使用该模式来匹配网址。我想你可以简单地使用
https?://\S+。我还会将您链接到一些替代方案here。 - 您正在使用2
preg_match_all()次来电和1次str_replace()来拨打相同的文字,您可以将其整理为1preg_replace()。 -
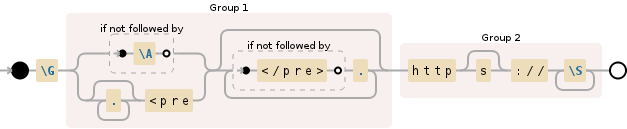
\G始终来自主题中的第一个匹配位置。 - 第1组
-
(?:(?!\A)|.*<pre)匹配字符串开头的第一个<pre标记,或者如果在此处找不到更多网址,则允许获取下一个<pre标记标签 -
(?:(?!</pre>).)*)消费<pre>标记内的所有字符。
-
- 第2组
-
(https?://\S+?)匹配1个网址。
-
<强>代码
$postbits = "
<pre>
http://www.google.com
http://w...content-available-to-author-only...o.com
http://www.microsoft.com/ <-- only this one clickable
</pre>";
$regex = '#\G((?:(?!\A)|.*<pre)(?:(?!</pre>).)*)(https?://\S+?)#isU';
$repl = '\1<a href="\2" target="_blank">\2</a>';
$postbits = preg_replace( $regex, $repl, $postbits);
<强>正则表达式
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?