获取没有小写字母的字符串末尾的子字符串
我有像:
这样的字符串[POS Purchase]
POS Signature Purchase International SKYPE COMMUNICATIO, LUXEMBOURG, LUX
或:
ATM Cash Withdrawal. Surcharge: -3.0 BNEAIR INT DP LSL4 2, BNE AIRPORT, AUS
我希望得到包含任何字符但小写字母的字符串的结尾。对于上面的两个例子,答案应该是:
SKYPE COMMUNICATIO, LUXEMBOURG, LUX
和
BNEAIR INT DP LSL4 2, BNE AIRPORT, AUS
如何使用正则表达式实现此目的?
3 个答案:
答案 0 :(得分:5)
根据您的需要,您正在寻找以下正则表达式:
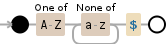
[^a-z]+$
否定字符类[^a-z]+将匹配任何无小写字符的组合,而锚$将使该正则表达式引擎与字符串的结尾匹配。
但请注意,这将与您的第二个示例中的-3.0匹配。如果您希望获得该值,则可以将[A-Z]置于正则表达式的前导位置:
[A-Z][^a-z]*$
您可以从这里开始了解有关正则表达式http://www.regular-expressions.info/
的更多信息答案 1 :(得分:3)
您可以使用此正则表达式:
[A-Z][A-Z\d, ]*$
以MULTILINE模式匹配您的数据。
这将匹配以大写字母开头的文本,后跟大写字母或数字或空格或逗号。
在Java中使用:
Pattern regex = Pattern.compile("(?m)[A-Z][A-Z\\d, ]*$");
答案 2 :(得分:1)
您可以使用以下自包含示例/模式匹配以大写单词字符开头且不包含任何小写字符的最后一个字符串:
String[] input = {
"[POS Purchase]" +
System.getProperty("line.separator") +
"POS Signature Purchase International SKYPE COMMUNICATIO, LUXEMBOURG, LUX",
"ATM Cash Withdrawal. Surcharge: -3.0 BNEAIR INT DP LSL4 2, BNE AIRPORT, AUS"
};
// | starts with uppercase letter
// | | uppercase letters or no letters
// | | | 0 or more times
// | | | | end of input
// | | | |
Pattern p = Pattern.compile("\\p{Lu}[\\p{Lu}\\P{L}]*$");
for (String s: input) {
Matcher m = p.matcher(s);
if (m.find()) {
System.out.println(m.group());
}
}
<强>输出
SKYPE COMMUNICATIO, LUXEMBOURG, LUX
BNEAIR INT DP LSL4 2, BNE AIRPORT, AUS
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?