我是python的初学者,并尝试使用Python 2.7创建一个程序,该程序从以下网站检索赔率。
英文版网站: http://bet.hkjc.com/racing/pages/odds_wp.aspx?date=24-09-2015&venue=hv&raceno=1&lang=en
中文版网站: bet.hkjc.com/racing/pages/odds_wp.aspx?date=24-09-2015&venue=hv&raceno=1
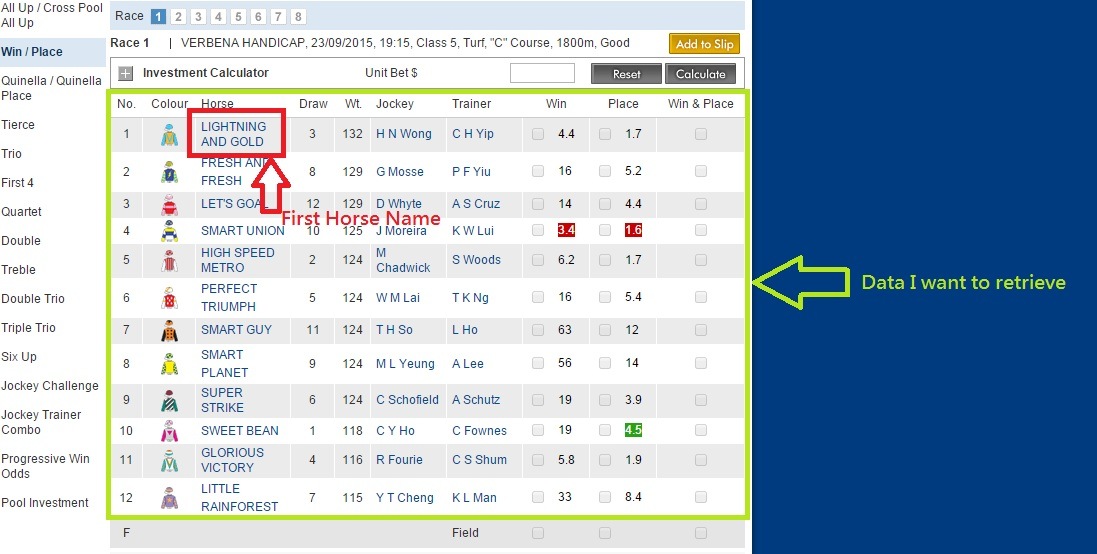
我想要检索的数据标记在以下图像文件中 https://na.cx/i/Bz873x.jpg
该程序在其他网站上运行良好(例如reddit或lxml.de/parsing.html)。 但我不知道为什么程序会检索到我使用Chrome检索到的不同html代码。
from urllib2 import urlopen
from lxml import etree
# print out the sources code of the web site
# work properly on other web sites (e.g. reddit.com or lxml.de/parsing.html)
# but having problem on the betting web site
url = 'http://bet.hkjc.com/racing/pages/odds_wp.aspx?date=24-09-2015&venue=hv&raceno=1'
tree = etree.HTML(urlopen(url).read())
print(etree.tostring(tree, pretty_print=True))
# printing the first horse name in chinese version web site (Doesn't work)
horse_name = tree.xpath('//*[@id="detailWPTable"]/table/tbody/tr[2]/td[3]/a/span/text()')
print horse
运行上述程序后,我发现Python检索到的html代码与我使用Chrome功能检索的html代码不同 - [查看源代码]或[打开开发人员工具]。
我的问题是
谢谢:)
答案 0 :(得分:0)
这可能是因为您的用户代理设置不同,并且页面上的某些脚本未执行。您可以在HTTP请求标头中设置第一个元素,但最重要的是,您需要使用headless browser来呈现网页。
Selenium是在Python中运行这种框架的一个很好的例子。
{kind=link}