正则表达式,用于在最后一个斜杠后过滤掉带有文字点的URL
我需要正则表达式来识别最后一个正斜杠之后的网址
-
有一个文字点,例如
http://www.example.es/cat1/cat2/some-example_DH148439#.Rh1-js_4 -
没有文字点,例如
http://www.example.es/cat1/cat2/cat3
到目前为止,我只找到了用于匹配^(.*[\\\/])之前或最后一个正斜杠之后的所有内容的正则表达式:[^/]+$以及匹配最后一个斜杠之后的文字点之后的所有内容{{1但是我无法提出上述内容,请帮忙。
3 个答案:
答案 0 :(得分:1)
好吧,像往常一样,使用正则表达式匹配URL是错误工作的错误工具。您可以使用urlparse(或python3中的urllib.parse)以非常pythonic的方式完成工作:
>>> from urlparse import urlparse
>>> urlparse('http://www.example.es/cat1/cat2/some-example_DH148439#.Rh1-js_4')
ParseResult(scheme='http', netloc='www.example.es', path='/cat1/cat2/some-example_DH148439', params='', query='', fragment='.Rh1-js_4')
>>> urlparse('http://www.example.es/cat1/cat2/cat3')
ParseResult(scheme='http', netloc='www.example.es', path='/cat1/cat2/cat3', params='', query='', fragment='')
如果你真的想要一个正则表达式,下面的正则表达式就是一个能回答你问题的例子:
import re
>>> re.match(r'^[^:]+://([^.]+\.)+[^/]+/([^/]+/)+[^#]+(#.+)?$', 'http://www.example.es/cat1/cat2/some-example_DH148439#.Rh1-js_4') != None
True
>>> re.match(r'^[^:]+://([^.]+\.)+[^/]+/([^/]+/)+[^#]+(#.+)?$', 'http://www.example.es/cat1/cat2/cat3') != None
True
但我给出的正则表达式足以回答你的问题,但不是验证URL或将其拆分的好方法。我要说的唯一的兴趣是实际回答你的问题。
这是正则表达式生成的自动机,以便更好地理解它:

要小心你的要求,因为JL的正则表达式不匹配:
http://www.example.es/cat1/cat2/cat3
在重读你的问题3×之后,你实际上要求以下正则表达式:
\/([^/]*)$
将匹配您的示例:
http://www.example.es/cat1/cat2/some-example_DH148439#.Rh1-js_4
http://www.example.es/cat1/cat2/cat3
@ jl-peyret建议,只是如何匹配/ 之后的一个小点,这会生成以下自动机:
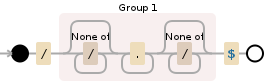
所以,无论你真正想要什么:
- 只要您可以匹配网址的某些部分,就使用urlparse
- 如果您正在尝试定义django路线,那么尝试匹配该片段是没有希望的
- 下次你提出问题时,请准确一点,并举例说明你的尝试:帮助我们帮助你。
答案 1 :(得分:1)
<?xml version="1.0" encoding="utf-8"?>
<resources>
<!-- Base application theme. -->
<style name="AppTheme" parent="@android:style/Theme.Material.Light">
<!-- Customize your theme here. -->
</style>
<style name="AppTheme.EditText">
<item name="android:colorControlNormal">@color/almanac_red_dark</item>
<item name="android:colorControlActivated">@color/almanac_red_light</item>
<item name="android:colorControlHighlight">@color/almanac_red_light</item>
</style>
<style name="AppTheme.CheckBox">
<item name="android:colorAccent">@color/almanac_red_dark</item>
</style>
</resources>
第一个/迫使你去照顾它。 $ force结束了字符串和 两个阶级否定都避免任何/之间。 检查@ https://regex101.com/
答案 2 :(得分:1)
我会像这样使用预测
(?=.*\.)([^/]+$)
(?= # Look-Ahead
. # Any character except line break
* # (zero or more)(greedy)
\. # "."
) # End of Look-Ahead
( # Capturing Group (1)
[^/] # Character not in [/] Character Class
+ # (one or more)(greedy)
$ # End of string/line
) # End of Capturing Group (1)
或像这样的负面预测
(?!.*\.)([^/]+$)
对于相反的情况
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?