从字符串中提取未加引号的文本
我有一个字符串,可能包含引用和不带引号的文本的随机段。例如,
s = "\"java jobs in delhi\" it software \"pune\" hello"。
我想在python中分离出这个字符串的引用和非引用部分。
所以,基本上我希望输出为:
quoted_string = "\"java jobs in delhi\"" "\"pune\""
unquoted_string = "it software hello"
我相信使用正则表达式是最好的方法。但我对正则表达式不是很好。是否有一些正则表达式可以帮助我解决这个问题? 或者有更好的解决方案吗?
4 个答案:
答案 0 :(得分:2)
我不喜欢像这样的正则表达式,为什么不使用像这样的分割呢?
s = "\"java jobs in delhi\" it software \"pune\" hello"
print s.split("\"")[0::2] # Unquoted
print s.split("\"")[1::2] # Quoted
答案 1 :(得分:2)
如果你的报价与你的例子一样基本,你可以分开;例如:
for s in (
'"java jobs in delhi" it software "pune" hello',
'foo "bar"',
):
result = s.split('"')
print 'text between quotes: %s' % (result[1::2],)
print 'text outside quotes: %s' % (result[::2],)
否则你可以尝试:
import re
pattern = re.compile(
r'(?<!\\)(?:\\\\)*(?P<quote>["\'])(?P<value>.*?)(?<!\\)(?:\\\\)*(?P=quote)'
)
for s in data:
print pattern.findall(s)
我解释了正则表达式(我在ihih中使用它):
(?<!\\)(?:\\\\)* # find backslash
(?P<quote>["\']) # any quote character (either " or ')
# which is *not* escaped (by a backslash)
(?P<value>.*?) # text between the quotes
(?<!\\)(?:\\\\)*(?P=quote) # end (matching) quote
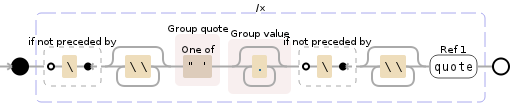
答案 2 :(得分:1)
使用正则表达式:
re.findall(r'"(.*?)"', s)
将返回
['java jobs in delhi', 'pune']
答案 3 :(得分:1)
你应该使用Python的shlex模块,这非常好:
>>> from shlex import shlex
>>> def get_quoted_unquoted(s):
... lexer = shlex(s)
... items = list(iter(lexer.get_token, ''))
... return ([i for i in items if i[0] in "\"'"],
[i for i in items if i[0] not in "\"'"])
...
>>> get_quoted_unquoted("\"java jobs in delhi\" it software \"pune\" hello")
(['"java jobs in delhi"', '"pune"'], ['it', 'software', 'hello'])
>>> get_quoted_unquoted("hello 'world' \"foo 'bar' baz\" hi")
(["'world'", '"foo \'bar\' baz"'], ['hello', 'hi'])
>>> get_quoted_unquoted("does 'nested \"quotes\" work' yes")
(['\'nested "quotes" work\''], ['does', 'yes'])
>>> get_quoted_unquoted("what's up with single quotes?")
([], ["what's", 'up', 'with', 'single', 'quotes', '?'])
>>> get_quoted_unquoted("what's up when there's two single quotes")
([], ["what's", 'up', 'when', "there's", 'two', 'single', 'quotes'])
我认为这个解决方案就像任何其他解决方案一样简单(基本上是一个oneliner,如果删除函数声明和分组)并且它可以很好地处理嵌套引号等。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?