我是Apache Spark的新手。
我的工作是读取两个CSV文件,从中选择一些特定列,合并,聚合并将结果写入单个CSV文件。
例如,
name,age,deparment_id
department_id,deparment_name,location
name,age,deparment_name
我正在将CSV加载到数据帧中。 然后能够使用dataframe
中存在的几种方法join,select,filter,drop来获取第三个数据帧
我也可以使用多个RDD.map()
我也可以使用hiveql
HiveContext来做同样的事情
我想知道如果我的CSV文件很庞大,为什么会有效?为什么?
答案 0 :(得分:12)
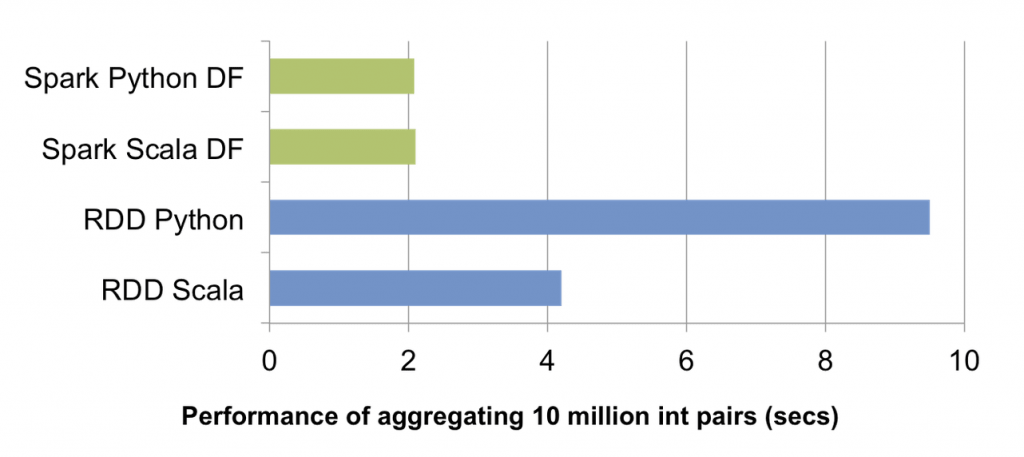
此博客包含基准测试。数据帧比RDD
更有效以下是博客
的摘录在高级别,有两种优化。首先,Catalyst应用逻辑优化,例如谓词下推。优化器可以将过滤器谓词下推到数据源中,使物理执行能够跳过不相关的数据。在Parquet文件的情况下,可以跳过整个块,并且可以通过字典编码将字符串上的比较转换为更便宜的整数比较。在关系数据库的情况下,谓词被下推到外部数据库中以减少数据流量。 其次,Catalyst将操作编译为物理计划以执行,并为那些通常比手写代码更优化的计划生成JVM字节码。例如,它可以在广播连接和随机连接之间智能地选择以减少网络流量。它还可以执行较低级别的优化,例如消除昂贵的对象分配和减少虚函数调用。因此,我们希望在迁移到DataFrames时,现有Spark程序的性能会有所提高。
以下是效果基准https://databricks.com/wp-content/uploads/2015/02/Screen-Shot-2015-02-16-at-9.46.39-AM.png
答案 1 :(得分:6)
使用催化剂引擎优化DataFrames和spark sql查询,因此我猜他们会产生类似的性能 (假设您使用的是版本> = 1.3)
两者都应该比简单的RDD操作更好,因为对于RDD,spark没有任何关于数据类型的知识,所以它不能做任何特殊的优化
答案 2 :(得分:0)
Spark的总体方向是使用数据框,以便通过催化剂优化查询
{kind=link}