使用RegEx解析文件名 - Python
我试图获得真实的"下载时,名称中的电影名称。 所以,例如,我有
Star.Wars.Episode.4.A.New.Hope.1977.1080p.BrRip.x264.BOKUTOX.YIFY
并希望得到
Star Wars Episode 4 A New Hope
所以我正在使用这个正则表达式:
.*?\d{1}?[ .a-zA-Z]*
效果很好,但仅适用于带有数字的电影,例如“钢铁侠3”和“钢铁侠3”。例如。 我希望能够收到像“星际之际”这样的电影。从
Interstellar.2014.1080p.BluRay.H264.AAC-RARBG
我现在得到了
Interstellar 2
我尝试了几种方法,并且已经花费了很多时间,但是如果你有任何关于如何做的建议/想法/提示,那么问你们是不是很伤心... 非常感谢!
4 个答案:
答案 0 :(得分:0)
根据您的示例并假设您始终在 1080p 下载(或知道该字段的值):
x = 'Interstellar.2014.1080p.BluRay.H264.AAC-RARBG'
y = x.split('.')
print " ".join(y[:y.index('1080p')-1])
忘记正则表达式(现在无论如何!)并使用固定字段布局。找到您认识的字段(1080p)并删除您不想要的信息(年份)。重新组合结果,你得到“星际”和“星球大战第4集新希望”。
答案 1 :(得分:0)
假设电影的文件名中总是有一个四位数年份或四位数分辨率表示法,一个简单的解决方案会替换不需要的部分:
“(?:\ | \ d {4,4} + $)”
通过空白,事后剥离()......
例如:
test1 = "Star.Wars.Episode.4.A.New.Hope.1977.1080p.BrRip.x264.BOKUTOX.YIFY"
test2 = "Interstellar.2014.1080p.BluRay.H264.AAC-RARBG"
res1 = re.sub(r"(?:\.|\d{4,4}.+$)",' ',test1).strip()
res2 = re.sub(r"(?:\.|\d{4,4}.+$)",' ',test2).strip()
print(res1, res2, sep='\n')
>>> Star Wars Episode 4 A New Hope
>>> Interstellar
答案 2 :(得分:0)
以下正则表达式可行(假设格式类似于moviename.year.1080p.anything或moviename.year.720p.anything:
.*(?=.\d{4}.*\d{3,}p)
Regex example(尝试单元测试以查看正则表达式)
<强>解释
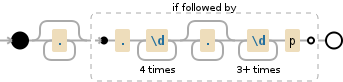
答案 3 :(得分:0)
\.(?=.*?(?:19|20)\d{2}\b)|(?:19|20)\d{2}\b.*$
使用re.sub尝试此操作。请参阅演示。
https://regex101.com/r/hR7tH4/10
import re
p = re.compile(r'\.(?=.*?(?:19|20)\d{2}\b)|(?:19|20)\d{2}\b.*$', re.MULTILINE)
test_str = "Star.Wars.Episode.4.A.New.Hope.1977.1080p.BrRip.x264.BOKUTOX.YIFY\nInterstellar.2014.1080p.BluRay.H264.AAC-RARBG\nIron Man 3"
subst = " "
result = re.sub(p, subst, test_str)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?