表情符号的正则表达式
http://jsfiddle.net/bxeLyneu/1/
function custom() {
var str = document.getElementById('original').innerHTML;
var replacement = str.replace(/\B:poop:\B/g,'REPLACED');
document.getElementById('replaced').innerHTML = replacement;
}
custom()
是=:大便:应替换为"更换" 否=:大便:不应该被替换。换句话说,保持不变。
第4,5,6号似乎不遵循所提供的规则。我知道为什么,但我不知道如何将多个表达式合并为一个。 我尝试了很多其他的但是我不能让它们像我希望的那样工作。赔率不利于我。
是的,这与Facebook聊天框中的表情符号非常相似。
新问题:

http://jsfiddle.net/xaekh8op/13/
/(^|\s):bin:(\s|$)/gm
无法扫描并替换中间的那个。 我该如何解决这个问题?
1 个答案:
答案 0 :(得分:4)
\B表示“任何位置不在单词边界”,而\s表示“空白”。根据您给出的示例,以下代码可以很好地运行。
function custom() {
var str = document.getElementById('original').innerHTML;
var replacement = str.replace(/([\s>]|^):poop:(?=[\s<]|$)/gm,'$1REPLACED');
document.getElementById('replaced').innerHTML = replacement;
}
custom()
http://jsfiddle.net/xaekh8op/15/
<强>解释
正则表达式([\s>]|^):poop:(?=[\s<]|$)代表以下内容:
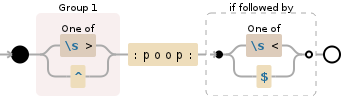 (在Debuggex中创建的图像)
(在Debuggex中创建的图像)
在开始时选择\s和>之一(或使用^表示行的开头),并将其分组为第1组,我们稍后可以使用它。同样适用于:poop:(\s或<或行尾$)之后。但是,第二次,它是使用前瞻((?= ...)是语法)来完成的,它会检查[\s<]|$部分之后是否存在,但它在替换中不会消耗它。 <和>会处理可能位于:poop:旁边的所有HTML标记。替换字符串$1中的$1REPLACED将第一个组放回,从而仅将:poop:替换为REPLACED。第二个“小组”只是一个前瞻,因此不需要更换。
有关字边界的更多信息,请参阅http://www.regular-expressions.info/wordboundaries.html,其中包含:
有三种不同的职位符合词边界:
- 在字符串中的第一个字符之前,如果第一个字符是单词字符。
- 在字符串中的最后一个字符之后,如果最后一个字符是单词字符。
- 字符串中的两个字符之间,其中一个是单词字符,另一个不是单词字符。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?