正则表达式提取由换行符分隔的两个字符串之间的字符串
我有一个如下字符串:
Movies(s):
DIE ANOTHER DAY
TOMORROW NEVER DIES
WORLD IS NOT ENOUGH
Running Date(s):
我想将电影名称提取为单独的匹配,而不是像下面那样整体提取:
Match 1: DIE ANOTHER DAY
Match 2: TOMORROW NEVER DIES
Match 3: WORLD IS NOT ENOUGH
我试图使用前瞻和后卫,但无法成功获得三场比赛。
4 个答案:
答案 0 :(得分:1)
这是一个单行:
String[] movies = str.replaceAll(".*Movies\\(s\\):\\s*|Running Date\\(s\\):.*", "").split("[\n\r]+");
此代码首先剥离正面/背面,只留下电影名称,然后分割(平台无关)换行符。
答案 1 :(得分:0)
你可以通过这样的正则表达式来利用丢弃技术:
.*:|^(.+)$
<强> Working demo
丢弃技术背后的想法是使用你想摆脱的模式链。所以,你可以这样:
discard patt1 | discard patt2 | discard pattN | (capture this)
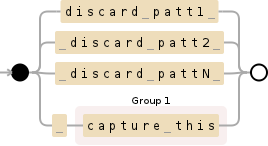
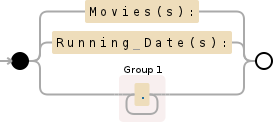
将此技术应用于您的字符串,您可以将上述正则表达式修改为以下内容:
Movies\(s\):|Running Date\(s\):|(.+)
discard--^ discard--^ capture--^
<强> Working demo
您可以使用此图轻松查看:
匹配信息
MATCH 1
1. [11-26] `DIE ANOTHER DAY`
MATCH 2
1. [27-46] `TOMORROW NEVER DIES`
MATCH 3
1. [47-66] `WORLD IS NOT ENOUGH`
您可以使用此Java代码:
Pattern regex = Pattern.compile(".*:|^(.+)$", Pattern.MULTILINE);
// or this line:
// Pattern regex = Pattern.compile("Movies\\(s\\):|Running Date\\(s\\):|(.+)", Pattern.MULTILINE);
Matcher regexMatcher = regex.matcher("YOUR STRING HERE");
if (regexMatcher.find()) {
System.out.println(regexMatcher.group(1));
}
答案 2 :(得分:0)
我使用以下正则表达式修复它:
(?s)(?<=Movie\(s\)\:\s{0,3}\r{0,1}\n.{0,100})([A-Z \.]+)(?=.{0,100}Running\Date\(s\)\:)
答案 3 :(得分:0)
String input = "Movies(s):\r\n" +
"DIE ANOTHER DAY\r\n" +
"TOMORROW NEVER DIES\r\n" +
"WORLD IS NOT ENOUGH\r\n" +
"Running Date(s):";
Pattern pattern = Pattern.compile("(([A-Z ]+)[\r\n]{1,2})");
Matcher m = pattern.matcher(input);
int index = 0;
while(m.find())
{
System.out.println(++index + "," + m.group(2));
}
输出将被(测试):
1,DIE ANOTHER DAY
2,TOMORROW NEVER DIES
3,WORLD IS NOT ENOUGH
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?