正则表达式模式将不同的变量分组
我一直在努力为字符串找到合适的正则表达式模式。
字符串是这样的:
0| DIMM: Hynix | Not installed | DIMM: Micron | DIMM: Hynix |
它也可能会变成这样的东西。
1| Not installed | DIMM: Samsung | DIMM: Hynix | DIMM: Hynix |
Dimm:变量可以改为三星,海力士,微米,甚至不安装。我想将每个单独分组,例如“Hynix”,“Micron”,“Samsung”和“Not installed”。我不想包括DIMM:在那里。
我试过这个,但只抓住了第一个变量。
(Not installed|(?<=DIMM:)\s[a-zA-Z]+)
复制粘贴它3次不会将其他变量分组。任何想法?
1 个答案:
答案 0 :(得分:1)
使用1个模式正则表达式,后面看
从您的正则表达式中汲取信息并利用 Stribizhev 评论,您还可以使用:
((?<=DIMM: )\w+|Not installed)
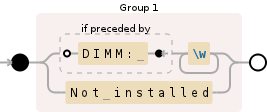
<强> Working demo
匹配信息
MATCH 1
1. [11-16] `Hynix`
MATCH 2
1. [26-39] `Not installed`
MATCH 3
1. [53-59] `Micron`
MATCH 4
1. [74-79] `Hynix`
MATCH 5
1. [92-105] `Not installed`
MATCH 6
1. [119-126] `Samsung`
MATCH 7
1. [140-145] `Hynix`
MATCH 8
1. [161-166] `Hynix`
使用4种模式正则表达式
我知道这不是一个漂亮的正则表达式,但可以帮助你这样做:
\|\s*(?:DIMM: )?(.*?)\s*\|\s*(?:DIMM: )?(.*?)\s*\|\s*(?:DIMM: )?(.*?)\s*\|\s*(?:DIMM: )?(.*?)\s*\|
<强> Working demo

使用此正则表达式将为您提供4个组中完整线捕获内容的匹配项。缺点是正则表达式非常难看。结果如下:
匹配信息
MATCH 1
1. [11-16] `Hynix`
2. [26-39] `Not installed`
3. [53-59] `Micron`
4. [74-79] `Hynix`
MATCH 2
1. [92-105] `Not installed`
2. [119-126] `Samsung`
3. [140-145] `Hynix`
4. [161-166] `Hynix`
使用1个模式正则表达式
刚刚找到了你可能会发现的另一个正则表达式:
\|\s*(?:DIMM:)?\s?(\w+\s?\w+)
<强> Working demo

此正则表达式仅使用1个捕获组,它比第一个短,但它被多次使用以匹配您想要的。因此,您必须添加更多逻辑来迭代您知道它属于完整行的前4个匹配项。结果如下:
匹配信息
MATCH 1
1. [11-16] `Hynix`
MATCH 2
1. [26-39] `Not installed`
MATCH 3
1. [53-59] `Micron`
MATCH 4
1. [74-79] `Hynix`
MATCH 5
1. [92-105] `Not installed`
MATCH 6
1. [119-126] `Samsung`
MATCH 7
1. [140-145] `Hynix`
MATCH 8
1. [161-166] `Hynix`
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?