Document doc = null;
try {
System.out.println("Postpage: "+postpage);
System.out.println("id: "+newid);
System.out.println("temp: "+tmp);
System.out.println("superslots: "+superslots);
doc = Jsoup.connect("http://www.ecostream.tv"+postpage+"/id="+newid+"&tpm="+tmp+superslots)
.userAgent("Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0")
.header("Accept","application/json, text/javascript, */*; q=0.01")
.header("Accept-Language","de,en-US;q=0.7,en;q=0.3")
.header("Accept-Encoding", "gzip, deflate")
.header("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8")
.header("X-Requested-With", "XMLHttpRequest")
.header("Referer", url)
//.timeout(3000)
.post();
System.out.println(doc.html());
} catch (IOException e1) {
e1.printStackTrace();
}
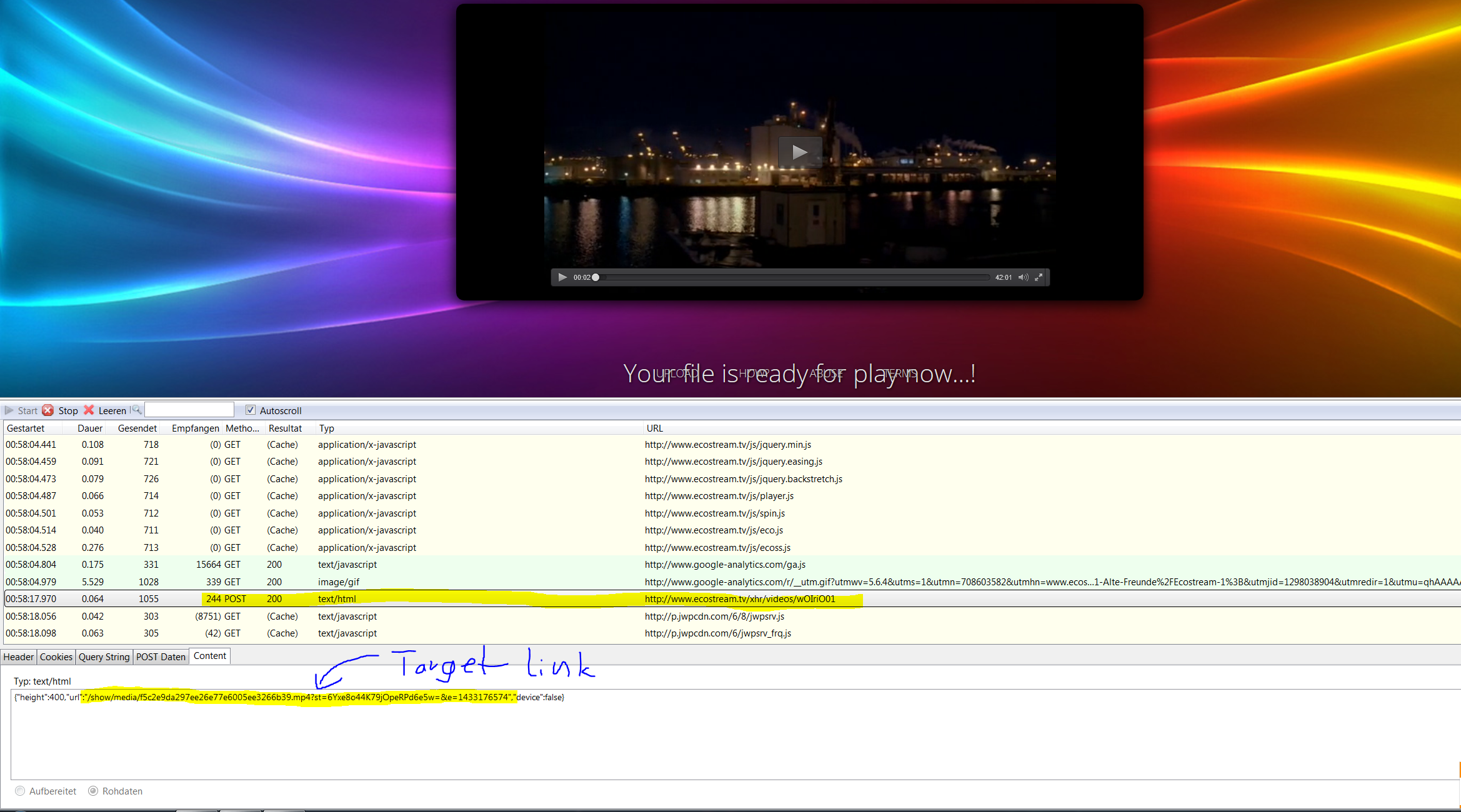
Pattern p3 = Pattern.compile("\"url\":\"(/[^<>\"]*?)\"");
Matcher m3 = p3.matcher(doc.html());
String finallink = null;
if(m3.find()){
finallink = m3.group(1);
}
return finallink;
з»ҷжҲ‘пјҡ
Postpage: /xhr/videos/wOIriO01
id: f5c2e9da297ee26e77e6005ee3266b39
temp: IdOxkBKqRyW
superslots: Hwh7_kuOyGg
org.jsoup.HttpStatusException: HTTP error fetching URL. Status=404, URL=http://www.ecostream.tv/xhr/videos/wOIriO01 /id=f5c2e9da297ee26e77e6005ee3266b39&tpm=IdOxkBKqRyWHwh7_kuOyGg
at org.jsoup.helper.HttpConnection$Response.execute(HttpConnection.java:459)
at org.jsoup.helper.HttpConnection$Response.execute(HttpConnection.java:434)
at org.jsoup.helper.HttpConnection.execute(HttpConnection.java:181)
at org.jsoup.helper.HttpConnection.get(HttpConnection.java:170)
at Hoster.EcoStream.getdownloadlink(EcoStream.java:117)
at Main.Main.main(Main.java:30)
Exception in thread "main" java.lang.NullPointerException
at Hoster.EcoStream.getdownloadlink(EcoStream.java:142)
at Main.Main.main(Main.java:30)
жүҖд»ҘжҲ‘еңЁеҒҡй”ҷзҡ„жҳҜHTTPFoxз»ҷжҲ‘зҡ„ж•ҙжҙҒзҡ„е—…жҺўе·Ҙе…·пјҡ
http://fs1.directupload.net/images/150601/48a9d95m.png
еӨҡж•°ж°‘дј—иөһжҲҗжҲ‘зҡ„зӣ®ж Үй“ҫжҺҘжҲ‘жғіиҜ»еҮәжқҘгҖӮ
{kind=link}