Python字符串连接与string.join的速度有多慢?
由于我在this thread的回答中的评论,我想知道+=运算符与''.join()之间的速度差异
那么两者之间的速度比较是什么?
5 个答案:
答案 0 :(得分:75)
来自:Efficient String Concatenation
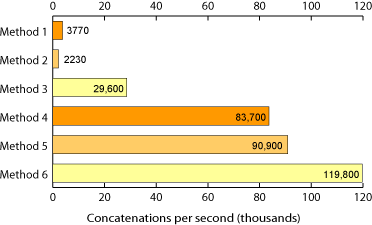
方法1:
def method1():
out_str = ''
for num in xrange(loop_count):
out_str += 'num'
return out_str
方法4:
def method4():
str_list = []
for num in xrange(loop_count):
str_list.append('num')
return ''.join(str_list)
现在我意识到它们并不具有严格的代表性,第4种方法会在迭代并加入每个项目之前附加到列表中,但这是一个公平的指示。
字符串连接比串联快得多。
为什么呢?字符串是不可变的,不能在适当的位置进行更改。要改变一个,需要创建一个新的表示(两者的串联)。
答案 1 :(得分:7)
我的原始代码是错误的,似乎+连接通常更快(特别是在较新的硬件上使用较新版本的Python)
时间如下:
Iterations: 1,000,000
Windows 7,Core i7上的Python 3.3
String of len: 1 took: 0.5710 0.2880 seconds
String of len: 4 took: 0.9480 0.5830 seconds
String of len: 6 took: 1.2770 0.8130 seconds
String of len: 12 took: 2.0610 1.5930 seconds
String of len: 80 took: 10.5140 37.8590 seconds
String of len: 222 took: 27.3400 134.7440 seconds
String of len: 443 took: 52.9640 170.6440 seconds
Windows 7上的Python 2.7,Core i7
String of len: 1 took: 0.7190 0.4960 seconds
String of len: 4 took: 1.0660 0.6920 seconds
String of len: 6 took: 1.3300 0.8560 seconds
String of len: 12 took: 1.9980 1.5330 seconds
String of len: 80 took: 9.0520 25.7190 seconds
String of len: 222 took: 23.1620 71.3620 seconds
String of len: 443 took: 44.3620 117.1510 seconds
在Linux Mint上,Python 2.7,一些较慢的处理器
String of len: 1 took: 1.8840 1.2990 seconds
String of len: 4 took: 2.8394 1.9663 seconds
String of len: 6 took: 3.5177 2.4162 seconds
String of len: 12 took: 5.5456 4.1695 seconds
String of len: 80 took: 27.8813 19.2180 seconds
String of len: 222 took: 69.5679 55.7790 seconds
String of len: 443 took: 135.6101 153.8212 seconds
以下是代码:
from __future__ import print_function
import time
def strcat(string):
newstr = ''
for char in string:
newstr += char
return newstr
def listcat(string):
chars = []
for char in string:
chars.append(char)
return ''.join(chars)
def test(fn, times, *args):
start = time.time()
for x in range(times):
fn(*args)
return "{:>10.4f}".format(time.time() - start)
def testall():
strings = ['a', 'long', 'longer', 'a bit longer',
'''adjkrsn widn fskejwoskemwkoskdfisdfasdfjiz oijewf sdkjjka dsf sdk siasjk dfwijs''',
'''this is a really long string that's so long
it had to be triple quoted and contains lots of
superflous characters for kicks and gigles
@!#(*_#)(*$(*!#@&)(*E\xc4\x32\xff\x92\x23\xDF\xDFk^%#$!)%#^(*#''',
'''I needed another long string but this one won't have any new lines or crazy characters in it, I'm just going to type normal characters that I would usually write blah blah blah blah this is some more text hey cool what's crazy is that it looks that the str += is really close to the O(n^2) worst case performance, but it looks more like the other method increases in a perhaps linear scale? I don't know but I think this is enough text I hope.''']
for string in strings:
print("String of len:", len(string), "took:", test(listcat, 1000000, string), test(strcat, 1000000, string), "seconds")
testall()
答案 2 :(得分:4)
现有的答案写得很好,研究得很好,但这是Python 3.6时代的另一个答案,因为现在我们有literal string interpolation(AKA,f - 字符串):< / p>
>>> import timeit
>>> timeit.timeit('f\'{"a"}{"b"}{"c"}\'', number=1000000)
0.14618930302094668
>>> timeit.timeit('"".join(["a", "b", "c"])', number=1000000)
0.23334730707574636
>>> timeit.timeit('a = "a"; a += "b"; a += "c"', number=1000000)
0.14985873899422586
使用CPython 3.6.5在2012年Retina MacBook Pro上进行测试,其中Intel Core i7为2.3 GHz。
这绝不是任何正式的基准测试,但它看起来像使用f - 字符串与使用+=连接的效果大致相同;当然,任何改进的指标或建议都是受欢迎的。
答案 3 :(得分:0)
这就是设计用于测试的愚蠢程序:)
使用加号
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a" + "b"
end = time.clock()
print "Time to run Plusser = ", end - start, "seconds"
输出:
Time to run Plusser = 1.16350010965 seconds
现在加入....
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a".join("b")
end = time.clock()
print "Time to run Joiner = ", end - start, "seconds"
输出:
Time to run Joiner = 21.3877386651 seconds
所以在Windows上的python 2.6上,我会说+比join快约18倍:)
答案 4 :(得分:0)
我重写了最后一个答案,请你在我测试的方式上分享你的意见吗?
import time
start1 = time.clock()
for x in range (10000000):
dog1 = ' and '.join(['spam', 'eggs', 'spam', 'spam', 'eggs', 'spam','spam', 'eggs', 'spam', 'spam', 'eggs', 'spam'])
end1 = time.clock()
print("Time to run Joiner = ", end1 - start1, "seconds")
start2 = time.clock()
for x in range (10000000):
dog2 = 'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'
end2 = time.clock()
print("Time to run + = ", end2 - start2, "seconds")
注意:此示例使用Python 3.5编写,其中range()的作用类似于前xrange()
我得到的输出:
Time to run Joiner = 27.086106206103153 seconds
Time to run + = 69.79100515996426 seconds
我个人更喜欢&#39; .join([])超过&#39; Plusser方式&#39;因为它更干净,更具可读性。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?