жҲ‘йңҖиҰҒдҪҝз”ЁNLTKд»ҺеҺҹе§Ӣж–Үжң¬дёӯиҺ·еҸ–еҸҘеӯҗдёӯзҡ„дҫқиө–е…ізі»гҖӮ жҚ®жҲ‘жүҖзҹҘпјҢstanfordи§ЈжһҗеҷЁе…Ғи®ёжҲ‘们еҸӘеҲӣе»әж ‘пјҢдҪҶжҳҜеҰӮдҪ•д»ҺиҝҷжЈөж ‘дёӯеҫ—еҲ°дҫқиө–е…ізі»жҲ‘жІЎжңүеҸ‘зҺ°пјҲд№ҹи®ёе®ғеҸҜиғҪпјҢд№ҹи®ёдёҚжҳҜпјү жүҖд»ҘжҲ‘ејҖе§ӢдҪҝз”ЁMaltParserгҖӮиҝҷжҳҜжҲ‘жӯЈеңЁдҪҝз”Ёзҡ„е’Ңе№ід»Јз Ғпјҡ
import os
from nltk.parse.stanford import StanfordParser
from nltk.tokenize import sent_tokenize
from nltk.parse.dependencygraph import DependencyGraph
from nltk.parse.malt import MaltParser
os.environ['JAVAHOME'] = r"C:\Program Files (x86)\Java\jre1.8.0_45\bin\java.exe"
os.environ['MALT_PARSER'] = r"C:\maltparser-1.8.1"
maltParser = MaltParser(r"C:\maltparser-1.8.1\engmalt.poly-1.7.mco")
class Parser(object):
@staticmethod
def Parse (text):
rawSentences = sent_tokenize(text)
treeSentencesStanford = stanfordParser.raw_parse_sents(rawSentences)
a=maltParser.raw_parse(rawSentences[0])
дҪҶжңҖеҗҺдёҖиЎҢжҠӣеҮәејӮеёёвҖң'str'еҜ№иұЎжІЎжңүеұһжҖ§'tag'вҖқ
changing the code above like this:
rawSentences = sent_tokenize(text)
treeSentencesStanford = stanfordParser.raw_parse_sents(rawSentences)
splitedSentences = []
for sentence in rawSentences:
splitedSentence = word_tokenize(sentence)
splitedSentences.append(splitedSentence)
a=maltParser.parse_sents(splitedSentences)
жҠӣеҮәзӣёеҗҢзҡ„ејӮеёёгҖӮ
жүҖд»ҘпјҢжҲ‘еҒҡй”ҷдәҶд»Җд№ҲгҖӮ В жҖ»зҡ„жқҘиҜҙпјҡжҲ‘жӯЈеңЁд»ҘжӯЈзЎ®зҡ„ж–№ејҸиҺ·еҫ—иҝҷж ·зҡ„дҫқиө–пјҡhttp://www.nltk.org/images/depgraph0.pngпјҲдҪҶжҲ‘йңҖиҰҒд»Һд»Јз Ғдёӯи®ҝй—®иҝҷдәӣдҫқиө–йЎ№пјү
Traceback (most recent call last):
File "E:\Google drive\Python multi tries\Python multi tries\Parser.py", line 51, in <module>
Parser.Parse("Some random sentence. Hopefully it will be parsed.")
File "E:\Google drive\Python multi tries\Python multi tries\Parser.py", line 32, in Parse
a=maltParser.parse_sents(splitedSentences)
File "C:\Python27\lib\site-packages\nltk-3.0.1-py2.7.egg\nltk\parse\malt.py", line 113, in parse_sents
tagged_sentences = [self.tagger.tag(sentence) for sentence in sentences]
AttributeError: 'str' object has no attribute 'tag'
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ0)
жӮЁдҪҝз”ЁдёҚеҗҲйҖӮзҡ„еҸӮж•°е®һдҫӢеҢ–MaltParserгҖӮ
иҝҗиЎҢhelp(MaltParser)дјҡжҸҗдҫӣд»ҘдёӢдҝЎжҒҜпјҡ
Help on class MaltParser in module nltk.parse.malt:
class MaltParser(nltk.parse.api.ParserI)
| Method resolution order:
| MaltParser
| nltk.parse.api.ParserI
| __builtin__.object
|
| Methods defined here:
|
| __init__(self, tagger=None, mco=None, working_dir=None, additional_java_args=None)
| An interface for parsing with the Malt Parser.
|
| :param mco: The name of the pre-trained model. If provided, training
| will not be required, and MaltParser will use the model file in
| ${working_dir}/${mco}.mco.
| :type mco: str
...
еӣ жӯӨпјҢеҪ“жӮЁи°ғз”ЁmaltParser = MaltParser(r"C:\maltparser-1.8.1\engmalt.poly-1.7.mco")ж—¶пјҢе…ій”®еӯ—еҸӮж•°taggerе°Ҷи®ҫзҪ®дёәйў„и®ӯз»ғжЁЎеһӢзҡ„и·Ҝеҫ„гҖӮ
дёҚе№ёзҡ„жҳҜпјҢиҝҷдёӘи®әзӮ№жІЎжңүи®°еҪ•пјҢдҪҶжҳҫ然е®ғжҳҜдёҖдёӘPoSж Үи®°еҷЁпјҢд»ҺжЈҖжҹҘжәҗеҸҜд»ҘзңӢеҮәгҖӮ
пјҲжӮЁдёҚеҝ…жҢҮе®ҡPoSж Үи®°еҷЁ;иҝҷжҳҜдёҖдёӘй»ҳи®Өзҡ„еҹәдәҺRegExзҡ„ж Үи®°еҷЁпјҢз”ЁдәҺеңЁиҜҘзұ»дёӯзЎ¬зј–з Ғзҡ„иӢұиҜӯгҖӮпјү
жүҖд»Ҙе°Ҷд»Јз Ғжӣҙж”№дёәmaltParser = MaltParser(mco=r"C:\maltparser-1.8.1\engmalt.poly-1.7.mco")пјҢдҪ еә”иҜҘжІЎй—®йўҳпјҲиҮіе°‘еңЁжүҫеҲ°дёӢдёҖдёӘй”ҷиҜҜд№ӢеүҚпјүгҖӮ
жӮЁзҡ„е…¶д»–й—®йўҳпјҡжҲ‘и®ӨдёәжӮЁе·Іиө°дёҠжӯЈиҪЁгҖӮеҰӮжһңжӮЁеҜ№дҫқиө–йЎ№ж„ҹе…ҙи¶ЈпјҢйӮЈд№Ҳе®һйҷ…дёҠжңҖеҘҪдҪҝз”Ёдҫқиө–йЎ№и§ЈжһҗпјҢе°ұеғҸжӮЁзҺ°еңЁжүҖеҒҡзҡ„йӮЈж ·гҖӮзЎ®е®һеҸҜд»Ҙе°ҶжҲҗеҲҶи§ЈжһҗиҪ¬жҚўдёәдҫқиө–пјҲиҝҷе·Іиў«иҜҒжҳҺпјүпјҢдҪҶе®ғеҸҜиғҪжӣҙеӨҡзҡ„е·ҘдҪңгҖӮ
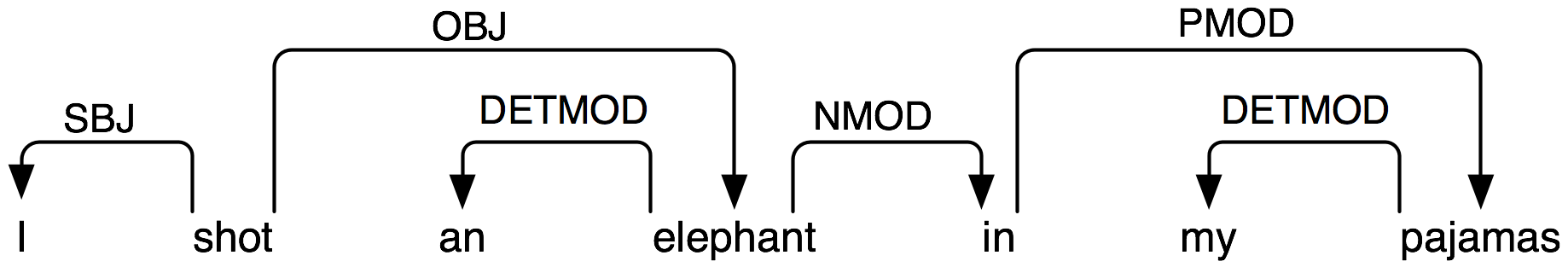{kind=link}