正则表达式匹配字符串运算符
我正在尝试创建一个与运算符^(xor)匹配的正则表达式,只要它充当两个字符串之间的运算符而不是字符串的一部分。
例如,拥有包含以下两行的文件:
'asdfasdf'; 'asdfasd'^'asdflkj';
['asdf', '^', 'asdf'];
只有第一个匹配,因为它是^不是字符串一部分的唯一一个。当它不在字符串中时,如何使正则表达式匹配^?
更新:我正在使用egrep。我需要一种方法来识别^是字符串的一部分还是不是字符串的一部分。我的最终目标是找到xor运算符何时用于字符串:类似于
('[^']'\^.+|.+\^'[^']')
但这符合我的例子的第二行。
因此,它应匹配如下字符串:
'asdf1524-sdfaA'^'sdfa322='
'sdfa22_'^$myvar
$myvar^'asAf34%'
但是它不匹配:
['+','*','^','%']
'^'=>2
"afa^sadfa"
UPDATE2 :再添加一个示例,说明为什么提议的awk解决方案不起作用。当使用单引号字符串操作时,我需要找到^运算符。我想在文件中找到它的出现次数,我想在bash脚本中添加这个检查。
提前致谢!
4 个答案:
答案 0 :(得分:1)
您想要做的是明确捕获字符串,这些字符串可能包含您 想要的^匹配然后丢弃该字符串。详细解释了here以及JavaScript示例here。
如果您正在使用PCRE正则表达式,您可以使用PCRE的(*SKIP)(*FAIL)选项立即丢弃麻烦的匹配项,否则您必须在捕获组中捕获它们,然后您可以检查它们并且丢弃整个匹配是捕获组不是空的。
(?:(['"])(?:(?!\1|\\).|\\.)*\1|\/\/[^\n]*(?:\n|$)|\/\*(?:[^*]|\*(?!\/))*\*\/)(*SKIP)(*FAIL)|\^
如果您需要根据捕获组手动丢弃匹配项,请执行以下操作:
((['"])(?:(?!\2|\\).|\\.)*\2|\/\/[^\n]*(?:\n|$)|\/\*(?:[^*]|\*(?!\/))*\*\/)|\^
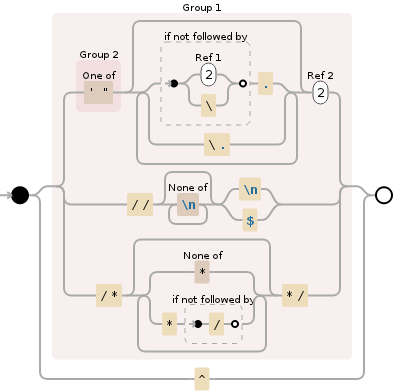
另请参阅Debuggex Demo,其中 要匹配的^是黄色的,表示它们不在捕获组中。所有其他匹配都有一个捕获组,并在Debuggex visual中突出显示。
注意:我添加了对/*...*/和//条评论的支持,但这些都没有说明PHP中的Heredoc/nowdoc字符串,也不知道如果这对您很重要,您可以将其添加到相当简单的另一个替代匹配中,该匹配应该被(*SKIP)(*FAIL)编辑或捕获并丢弃。
答案 1 :(得分:1)
使用带有字段的awk和一个简单的正则表达式而不是带有复杂正则表达式的grep,例如使用此线程中到目前为止建议的所有示例输入:
$ cat file
'asdfasdf'; 'asdfasd'^'asdflkj'; YES
['asdf', '^', 'asdf']; NO
''o'^'o'' NO
'asdf1524-sdfaA'^'sdfa322=' YES
'sdfa22_'^$myvar YES
$myvar^'asAf34%' YES
['+','*','^','%'] NO
'^'=>2 NO
'asdfa5A_sdf'; 'asd5A_fasd'^'asd5A_flkj'; YES
'asdfa5A_'^$var1; YES
$var2^'asdfa5A_'; YES
'asdf', '^', 'asdf'; NO
'+', '-', '*', '/', '^', '_'); NO
'+'=>0,'-'=>0,'*'=>0,'/'=>0,'^'=>1); NO
'+'=>0,'-'=>0,'*'=>1,'/'=>1,'_'=>1,'^'=>2); NO
'+', '-', '*', '/', '^'))) { NO
$ awk -F"'" '{for (i=1;i<=NF;i+=2) if ($i ~ /\^/) {print; next}}' file
'asdfasdf'; 'asdfasd'^'asdflkj'; YES
'asdf1524-sdfaA'^'sdfa322=' YES
'sdfa22_'^$myvar YES
$myvar^'asAf34%' YES
'asdfa5A_sdf'; 'asd5A_fasd'^'asd5A_flkj'; YES
'asdfa5A_'^$var1; YES
$var2^'asdfa5A_'; YES
以上工作方法是将每个'的每一行拆分成一系列字段,这样奇数编号的字段在引号对之外,而偶数编号的字段在引号对中(例如out'in'out'in'out)和那么你只需在奇数场中寻找^。
如果可能的话,这需要更多的工作来处理字符串中的换行符和/或转义引号,但到那时你真的应该看一个语言解析器而不是shell脚本。
答案 2 :(得分:0)
这样的事情:^[^^,]+?(?<!')'?\^'?(?!')[^^,]+?$应该做你想做的事。有一个例子here。
答案 3 :(得分:0)
我需要在grep中使用它,所以pcre不能正常工作(即使使用pgrep)。 我最终使用了一个令人难以置信的丑陋且不常用的正则表达式:
^[^']*((('[^']*){1}|('[^']*){3}|('[^']*){5}|('[^']*){7}|('[^']*){9}|('[^']*){11})[^']+'\^.+|(('[^']*){0}|('[^']*){2}|('[^']*){4}|('[^']*){6}|('[^']*){8}|('[^']*){10})[^']+\^'.+)
这适用于在运算符之前声明的最多5个字符串,并最终比较[^']+\^'.+或[^']+'\^.+。我知道,我知道......但这是我发现使它工作的唯一方法,当然只适用于单引号字符串。
它完全适用于此示例文件:
'asdfa5A_sdf'; 'asd5A_fasd'^'asd5A_flkj';
'asdfa5A_'^$var1;
$var2^'asdfa5A_';
'asdf', '^', 'asdf';
'+', '-', '*', '/', '^', '_');
'+'=>0,'-'=>0,'*'=>0,'/'=>0,'^'=>1);
'+'=>0,'-'=>0,'*'=>1,'/'=>1,'_'=>1,'^'=>2);
'+', '-', '*', '/', '^'))) {
欢迎更好的解决方案:)。 感谢所有帮助我的人,特别是@npinti,他花了很多时间来检查这个!
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?