使用r从(地址)字符串中提取房屋号码
我想将地址解析(提取)到HouseNumber和Streetname。 我以后应该能够写出提取的"值"进入新栏目(商店$ HouseNumber和商店$ Streetname)。
所以我想说我有一个名为" shop":
的数据框> shops
Name city street
1 Something Fakecity New Street 3
2 SomethingOther Fakecity Some-Complicated-Casestreet 1-3
3 SomethingDifferent Fakecity Fake Street 14a
那么有没有办法将街道列分成两个列表,一个是街道名称,一个是门牌号码,包括" 1-3"," 14a"等等最后,结果可以分配给数据框,看起来像。
> shops
Name city Streetname HouseNumber
1 Something Fakecity New Street 3
2 SomethingOther Fakecity Some-Complicated-Casestreet 1-3
3 SomethingDifferent Fakecity Fake Street 14a
示例:Easyfakestreet 5 - > Easyfakestreet,5
由于我的一些街道字符串将具有带连字符的街道地址并且具有非数字组件,因此稍微复杂一些。
示例:新街3 - > ['新街',' 3']
一些复杂的案例街1-3 - > ['一些-复杂-Casestreet'' 1-3']
假街14a - > ['假街',' 14a']
我会感激一些帮助!
5 个答案:
答案 0 :(得分:8)
这是一个可能的tidyr解决方案
library(tidyr)
extract(df, "street", c("Streetname", "HouseNumber"), "(\\D+)(\\d.*)")
# Name city Streetname HouseNumber
# 1 Something Fakecity New Street 3
# 2 SomethingOther Fakecity Some-Complicated-Casestreet 1-3
# 3 SomethingDifferent Fakecity Fake Street 14a
答案 1 :(得分:5)
您可以尝试:
shops$Streetname <- gsub("(.+)\\s[^ ]+$","\\1", shops$street)
shops$HousNumber <- gsub(".+\\s([^ ]+)$","\\1", shops$street)
数据
shops$street
#[1] "New Street 3" "Some-Complicated-Casestreet 1-3" "Fake Street 14a"
<强>结果
shops$Streetname
#[1] "New Street" "Some-Complicated-Casestreet" "Fake` Street"
shops$HousNumber
#[1] "3" "1-3" "14a"
答案 2 :(得分:2)
创建一个模式,其背面引用与街道和数字相匹配,然后使用sub依次替换每个反向引用。不需要包裹:
pat <- "(.*) (\\d.*)"
transform(shops,
street = sub(pat, "\\1", street),
HouseNumber = sub(pat, "\\2", street)
)
,并提供:
Name city street HouseNumber
1 Something Fakecity New Street 3
2 SomethingOther Fakecity Some-Complicated-Casestreet 1-3
3 SomethingDifferent Fakecity Fake Street 14a
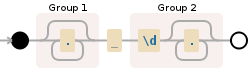
以下是pat:
(.*) (\d.*)
注意:
1)我们将此用于shops:
shops <-
structure(list(Name = c("Something", "SomethingOther", "SomethingDifferent"
), city = c("Fakecity", "Fakecity", "Fakecity"), street = c("New Street 3",
"Some-Complicated-Casestreet 1-3", "Fake Street 14a")), .Names = c("Name",
"city", "street"), class = "data.frame", row.names = c(NA, -3L))
2)David Arenburg的模式可以在这里交替使用。只需将pat设置为它即可。上面的模式的优点是它允许在其中嵌入数字的街道名称,但大卫的优点是在街道号码之前可能缺少空间。
答案 3 :(得分:0)
您可以使用软件包 unglue
library(unglue)
unglue_unnest(shops, street, "{street} {value=\\d.*}")
#> Name city street value
#> 1 Something Fakecity New Street 3
#> 2 SomethingOther Fakecity Some-Complicated-Casestreet 1-3
#> 3 SomethingDifferent Fakecity Fake Street 14a
由reprex package(v0.3.0)于2019-10-08创建
答案 4 :(得分:0)
国际地址非常复杂的问题
$re = '/(\d+[\d\/\-\. ,]*[ ,\d\-\w]{0,2} )/m';
$str = '234 Test Road, Testville
456b Tester Road, Testville
789 c Tester Road, Testville
Mystreet 14a
123/3 dsdsdfs
Roobertinkatu 36-40
Flats 1-24 Acacia Avenue
Apartment 9D, 1 Acacia Avenue
Flat 24, 1 Acacia Avenue
Moscow Street, plot,23 building 2
Apartment 5005 no. 7 lane 31 Wuming Rd
Quinta da Redonda Lote 3 - 1 º
102 - 3 Esq
Av 1 Maio 16,2 dt,
Rua de Ceuta Lote 1 Loja 5
11334 Nc Highway 72 E ';
preg_match_all($re, $str, $matches, PREG_SET_ORDER, 0);
// Print the entire match result
var_dump($matches);
{kind=link}
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?