Spark - 检查点对性能的影响
在Spark的DStreamCheckpointData中,似乎检查点机制收集要检查点的time窗口并将其更新/写入检查点文件。我想特别了解几件事情:
-
在每个检查点间隔,它是否读取所有先前的检查点数据,然后更新当前状态?如果是这样,当检查点状态变得非常大时,对性能的影响是什么,这肯定会减慢长时间运行的流上下文。
-
是否有任何通用规则或公式来计算不同数据提取率,滑动窗口和批处理间隔的检查点间隔?
1 个答案:
答案 0 :(得分:10)
-
是的,检查点是一种阻止操作,因此它在活动期间停止处理。这种状态序列化停止计算的时间长度取决于你写这个的媒体的写入性能(你听说过Tachyon / Alluxio吗?)。
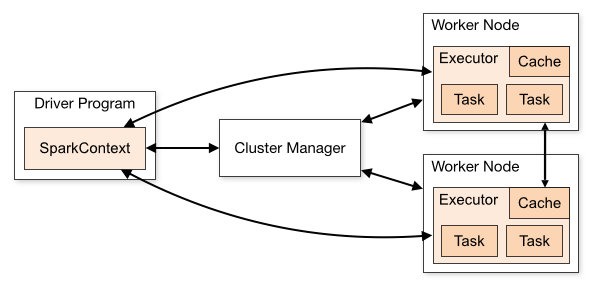
另一方面,每次新的检查点操作都不会读取先前的检查点数据:当正在操作流时,有状态信息已经在Spark的高速缓存中维护(检查点只是它的备份) 。让我们想象一下最简单的状态,即所有整数的总和,在整数流中遇到:在每个批次上,你根据批量中看到的数据计算这个总和的新值 - 你可以将此部分和存储在缓存中(参见上文)。每五批左右(取决于您的检查点间隔),您将此总和写入磁盘。现在,如果在后续批处理中丢失了一个执行程序(一个分区),则可以通过仅为最后五个分区重新处理此执行程序的分区来重建总计(通过读取磁盘以查找最后一个检查点) ,并重新处理最后五批的缺失部分。但在正常处理(无事件)中,您无需访问磁盘。
-
我知道没有通用公式,因为您必须修复您愿意从中恢复的最大数据量。旧文档提供了a rule of thumb。
但在流媒体的情况下,您可以将批处理间隔视为计算预算。我们假设您的批处理间隔为30秒。在每个批处理上,您有30秒的时间来分配写入磁盘或计算(批处理时间)。为确保您的工作稳定,您必须确保批处理时间不会超出预算,否则您将填满群集的内存(如果需要35秒才能处理并且#34;刷新&#34 ; 30秒的数据,在每个批次上,你摄取的数据比同时刷新的数据多 - 因为你的记忆是有限的,这最终会导致溢出。)
假设您的平均批处理时间为25秒。因此,在每个批次中,您的预算中有5秒的未分配时间。您可以将其用于检查点。现在考虑检查点需要多长时间(你可以从Spark UI中取笑)。 10秒? 30秒 ?等一下 ?
如果在
c秒批处理间隔内检查点需要bi秒,并且批处理时间为bp秒,您将"恢复"来自检查点(处理在未处理期间仍然进入的数据):ceil(c / (bi - bp))批次。如果您需要
k批次来恢复&#34;从检查点开始(即恢复从检查点引起的迟到),并且您正在检查每个p批次,您需要确保强制执行k < p,以避免不稳定的工作。所以在我们的例子中:-
所以如果你需要10秒钟检查点,你需要10 /(30 - 25)= 2批次来恢复,所以你可以每2批次检查一次(或更多,即不那么频繁,我会建议说明计划外的时间损失。
-
所以如果检查点需要30秒,则需要30 /(30 - 25)= 6批次来恢复,所以你可以每6批(或更多)检查一次。
< / LI> -
如果检查点需要60秒,您可以每12批(或更多)检查一次。
-
请注意,这假设您的检查点时间是常数,或者至少可以受最大常数限制。遗憾的是,情况往往并非如此:一个常见的错误是忘记使用updateStatebyKey或mapWithState之类的操作删除有状态流中的部分状态 - 但状态的大小应始终有界。请注意,在多租户群集上,写入磁盘所花费的时间并不总是一个常量 - 其他作业可能会尝试在同一个执行器上同时访问磁盘,使您从磁盘iops中挨饿(在this talk Cloudera报告IO中在&gt; 5个并发写入线程之后,吞吐量显着降低。
请注意,您应设置检查点间隔,因为默认值是在最后一批之后发生超过default checkpoint interval的第一批 - 即10秒。对于30秒批处理间隔的示例,这意味着您每隔一个批处理检查一次。由于纯容错原因(如果重新处理几批产品并不会产生巨大的成本),它通常太频繁,即使按照您的计算预算允许,也会导致性能出现以下类型的峰值图:

- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?