如何告诉正则表达式不匹配组?
我在学习过程中正在进行一些正则表达式的实验。
输入为:I am ironman and I was batman and I will be superman
我希望匹配除batman
我尝试[^(batman)]+,但它与字符串
a,b,m,n,t都不匹配
我怎样才能实现它?
3 个答案:
答案 0 :(得分:5)
- 很高兴你学习正则表达式,但这样做太过分了,因为你可以轻松利用javascript的巨大超自然力量。
- 在大多数情况下 和 可读比正则表达式相同。
- 自费排除蝙蝠侠:)
- 这里是你如何做到的,没有正则表达式。我确定有人也会发布正则表达式的答案。
好吧,还有废话,这里是代码:
var words = input.split(" ").filter(function(str){
return str.toLowerCase() !== "batman";
});
答案 1 :(得分:4)
有几种方法可以:
带有负前瞻断言(?!...) (未跟随):
\b(?!batman\b)\w+
使用捕获组(您必须仅考虑捕获组1):
\b(?:batman\b|(\w+))
为什么你的模式不起作用:
你写了[^(batman)]但是一个字符类只是一个没有顺序的字符集合,你不能描述其中的子字符串。它与[^abmnt()]
答案 2 :(得分:3)
您可以使用丢弃技术。例如,您可以使用此模式:
batman|(\w+)
然后你将把这些单词存储在捕获组中。
<强> Working demo

正如您在屏幕截图中看到的那样,绿色的单词是使用捕获组捕获的,而蓝色的batman则被丢弃。
匹配信息:
MATCH 1
1. [0-1] `I`
MATCH 2
1. [2-4] `am`
MATCH 3
1. [5-12] `ironman`
MATCH 4
1. [13-16] `and`
MATCH 5
1. [17-18] `I`
MATCH 6
1. [19-22] `was`
MATCH 7
1. [30-33] `and`
MATCH 8
1. [34-35] `I`
MATCH 9
1. [36-40] `will`
MATCH 10
1. [41-43] `be`
MATCH 11
1. [44-52] `superman`
丢弃模式的另一个例子是,如果您要放弃batman和superman,那么您可以使用:
batman|superman|(\w+)
Debuggex 做得很好:
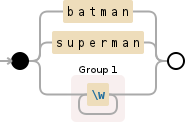
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?