жӯЈеҲҷиЎЁиҫҫејҸжҚ•иҺ·йҮҚеӨҚзҡ„зҹӯиҜӯ
жҲ‘еҸҜд»ҘдҪҝз”Ёд»ҘдёӢж–№жі•иҪ»жқҫжҚ•жҚүйҮҚеӨҚзҡ„еҚ•иҜҚпјҡ
"(?i)\\b(\\w+)(((\\.{3}\\s*|,\\s+)*|\\s+)\\1)+\\b"дҪҶжҳҜиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸдјјд№ҺжІЎжңүжү©еұ•еҲ°еӨҡдёӘеҚ•иҜҚпјҲдёәд»Җд№Ҳе®ғеә”иҜҘеӨ„дәҺеҪ“еүҚзҠ¶жҖҒпјүгҖӮеҰӮдҪ•дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжүҫеҲ°йҮҚеӨҚзҡ„зҹӯиҜӯпјҹ
еңЁиҝҷйҮҢпјҢжҲ‘жҸҗеҸ–йҮҚеӨҚзҡ„жңҜиҜӯпјҲж— и®әжғ…еҶөеҰӮдҪ•пјүпјҢдҪҶеҗҢж ·зҡ„жӯЈеҲҷиЎЁиҫҫејҸ并没жңүжҸҗеҲ°йҮҚеӨҚзҡ„зҹӯиҜӯпјҡ
library(qdapRegex)
rm_default("this is a big Big deal", pattern = "(?i)\\b(\\w+)(((\\.{3}\\s*|,\\s+)*|\\s+)\\1)+\\b", extract=TRUE)
rm_default("this is a big is a Big deal", pattern = "(?i)\\b(\\w+)(((\\.{3}\\s*|,\\s+)*|\\s+)\\1)+\\b", extract=TRUE)
жҲ‘еёҢжңӣжңүдёҖдёӘеҸҜд»Ҙиҝ”еӣһзҡ„жӯЈеҲҷиЎЁиҫҫејҸпјҡ
"is a big is a Big"
жңүпјҡ
x <- "this is a big is a Big deal"
дёәдәҶиҰҶзӣ–и§’иҗҪзҡ„жғ…еҶөпјҢиҝҷйҮҢйңҖиҰҒжӣҙеӨ§зҡ„жөӢиҜ•е’Ңиҫ“еҮә...
"this is a big is a Big deal",
"I want want to see",
"I want, want to see",
"I want...want to see see how",
"this is a big is a Big deal for those of, those of you who are.",
"I like it. It is cool",
)
[[1]]
[1] "is a big is a Big"
[[2]]
[1] "want want"
[[3]]
[1] "want, want"
[[4]]
[1] "want...want" "see see"
[[5]]
[1] "is a big is a Big" "those of, those of"
[[6]]
[1] NA
жҲ‘зҺ°еңЁзҡ„жӯЈеҲҷиЎЁиҫҫејҸеҸӘиғҪи®©жҲ‘пјҡ
rm_default(y, pattern = "(?i)\\b(\\w+)(((\\.{3}\\s*|,\\s+)*|\\s+)\\1)+\\b", extract=TRUE)
## [[1]]
## [1] NA
##
## [[2]]
## [1] "want want"
##
## [[3]]
## [1] "want, want"
##
## [[4]]
## [1] "want...want" "see see"
##
## [[5]]
## [1] NA
2 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ3)
жҲ‘и®Өдёәиҝҷж ·еҒҡз¬ҰеҗҲжӮЁзҡ„иҰҒжұӮпјҲиҜ·жіЁж„ҸпјҢжҲ‘们еҸӘе…Ғи®ёдҪҝз”ЁдёҖдёӘз©әж ј...жҲ–,дҪңдёәеҲҶйҡ”з¬ҰпјҢдҪҶжӮЁеә”иҜҘиғҪеӨҹиҪ»жқҫи°ғж•ҙе®ғпјүпјҡ
pattern <- "(?i)\\b(\\w.*)((?:\\s|\\.{3}|,)+\\1)+\\b"
rm_default(x, pattern = pattern, extract=TRUE)
дә§ең°пјҡ
[[1]]
[1] "is a big is a Big"
[[2]]
[1] "want want"
[[3]]
[1] "want, want"
[[4]]
[1] "want...want" "see see"
[[5]]
[1] "is a big is a Big" "those of, those of"
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ1)
иҜ•иҜ•иҝҷдёӘпјҡ
> regmatches(x, gregexpr("(?i)\\b(\\S.*\\S)[ ,.]*\\b(\\1)", x, perl = TRUE))
[[1]]
[1] "is a big is a Big"
[[2]]
[1] "want want"
[[3]]
[1] "want, want"
[[4]]
[1] "want...want" "see see"
[[5]]
[1] "is a big is a Big" "those of, those of"
иҝҷжҳҜдёҖдёӘеҸҜи§ҶеҢ–пјҲйҷӨдәҶеҸҜи§ҶеҢ–дёӯзҡ„й”ҷиҜҜ - \SйғЁеҲҶеә”иҜҘеңЁз»„еҶ…гҖӮ
(?i)\b(\S.*\S)[ ,.]*\b(\1)
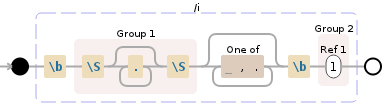
жӮЁеҸҜиғҪеёҢжңӣе°Ҷ[ ,.]жӣҝжҚўдёә[ [:punct:]]гҖӮжҲ‘жІЎжңүиҝҷж ·еҒҡпјҢеӣ дёәdebuggexдёҚж”ҜжҢҒPOSIXеӯ—з¬Ұз»„гҖӮ
- жҚ•иҺ·йҮҚеӨҚз»„зҡ„еӨҡдёӘеӯҗз»„
- PythonйҮҚеӨҚжҚ•иҺ·з»„
- RegExеҢ№й…ҚзҹӯиҜӯ并еҲӣе»әжҚ•иҺ·з»„
- жӯЈеҲҷиЎЁиҫҫејҸдёҖдёӘжҺҘдёҖдёӘжҚ•иҺ·еӨҡдёӘзҹӯиҜӯ
- Php preg_matchеҸӘжҚ•иҺ·зү№е®ҡзҡ„зҹӯиҜӯ
- жӯЈеҲҷиЎЁиҫҫејҸжҚ•иҺ·йҮҚеӨҚзҡ„зҹӯиҜӯ
- еҰӮдҪ•дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҹҘжүҫйҮҚеӨҚзҡ„зҹӯиҜӯпјҹ
- жӯЈеҲҷиЎЁиҫҫејҸжҚ•иҺ·йҮҚеӨҚжЁЎејҸ
- Javascript-жҚ•иҺ·йҮҚеӨҚеәҸеҲ—пјҹ
- еҰӮдҪ•з”ЁдёҖдёӘжӣҝжҚўйҮҚеӨҚзҡ„зҹӯиҜӯ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ