如何将单个列中的内容拆分为R中的两个单独列?
我的数据框中有一列:
Colname
20151102
19920311
20130204
>=70
60-69
20-29
我希望将此列拆分为两列,如:
Col1 Col2
20151102
19920311
20130204
>=70
60-69
20-29
如何实现这一结果?
3 个答案:
答案 0 :(得分:3)
一种可能的解决方案,想法是使用extract中的tidyr。请注意,我选择的分隔符(点)不得出现在您的初始data.frame。
library(magrittr)
library(tidyr)
df$colname = df$colname %>%
grepl("[>=|-]+", .) %>%
ifelse(paste0(".", df$colname), paste0(df$colname, "."))
extract(df, colname, c("col1","col2"), "(.*)\\.(.*)")
# col1 col2
#1 222222
#2 1111111
#3 >=70
#4 60-69
#5 20-29
数据:
df = data.frame(colname=c("222222","1111111",">=70","60-69","20-29"))
答案 1 :(得分:3)
无需任何包装:
df[,c("Col1", "Col2")] <- ""
isnum <- suppressWarnings(!is.na(as.numeric(df$colname)))
df$Col1[isnum] <- df$colname[isnum]
df$Col2[!isnum] <- df$colname[!isnum]
df <- df[,!(names(df) %in% "colname")]
数据:
df = data.frame(colname=c("20151102","19920311","20130204",">=70","60-69","20-29"), stringsAsFactors=FALSE)
答案 2 :(得分:1)
这是一个单一的声明解决方案。 read.pattern分别在括号括起的正则表达式部分中捕获两种字段类型。如果format列已经是类Colname,则可以省略"character"。此外,如果希望第一列是数字,则省略colClasses参数。)
library(gsubfn)
read.pattern(text = format(DF$Colname), pattern = "(^\\d+$)|(.*)",
col.names = c("Col1", "Col2"), colClasses = "character")
,并提供:
col1 col2
1 20151102
2 19920311
3 20130204
4 >=70
5 60-69
6 20-29
注意:以下是使用的正则表达式的可视化:
(^\d+$)|(.*)
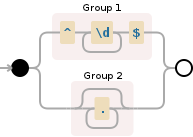
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?