使用正则表达式</form>从html文本中过滤<form>
我从ajax请求获取整个html页面作为文本(xmlhttp.responseText)
然后过滤文本以从该文本和该表单中的所有内容中提取html form。
我写了一个正则表达式:
text.match(/(<form[\W\w]*<\/form>)/gim)
由于我不是正则表达式的专家,所以我无法确定它是否适用于所有情况并将所有内容都放在form标记内?
有没有更好的方法可以说正则表达式中的一切? 所以正则表达式看起来像
text.match(/(<form[__everything_syntaxt_here__]*<\/form>)/gim)
2 个答案:
答案 0 :(得分:1)
试试这个:
function stripForm(s) {
var div = document.createElement('div');
div.innerHTML = s;
var scripts = div.getElementsByTagName('form');
var i = scripts.length;
while (i--) {
scripts[i].parentNode.removeChild(scripts[i]);
}
return div.innerHTML;
}
function getForm(s) {
var div = document.createElement('div');
div.innerHTML = s;
var scripts = div.getElementsByTagName('form');
var i = scripts.length;
var ret="";
while (i--) {
ret += scripts[i].innerHTML;
}
return ret;
}
var a = 'before Form <form action="" method="post"> <input type="text" /> <input type="text" /> <input type="text" /> </form><br/> after form';
alert(getForm(a));
alert(stripForm(a));
console.log(stripForm(a));
答案 1 :(得分:1)
不得不处理IE 5 ,你的灵魂很差。
快速回答您的问题 [\W\w]真的是绝对匹配所有内容的最佳方法吗?
是,JavaScript不支持s修饰符,以使.匹配换行符。做[\W\w]基本上告诉正则表达式:&#34;匹配任何单词字符,或任何不是单词字符&#34; 的东西,你可以看到绝对每一个角色属于这两个类别。
但是,如果您想要一个更可靠的解决方案来处理页面上的<!-- html comments -->和多个表单,最好的方法就像 this SO answer < / strong>但已针对HTML进行了更改。
这就是我要用的:
<!--(?:(?!-->)[\w\W])*-->|(<form(?:(?:(?!<\/form>|<!--)[\w\W])|(?:<!--(?:(?!-->)[\w\W])*-->))*</form>)
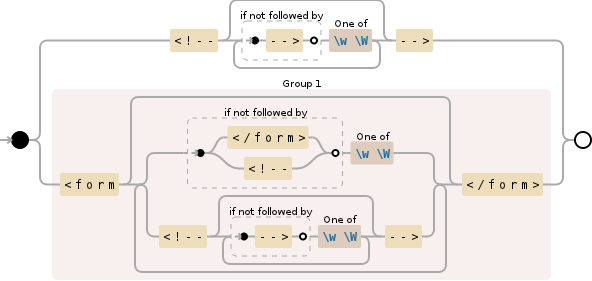
查看Debuggex Demo,了解您实际获得的匹配项。在JavaScript中,您可以期待第一个捕获组。如果它是空的,那就是删除评论的表单,如解释 here 。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?