将ISIN解析为String
我想用一个非常奇怪的字符串解析ISIN,我的代码看起来像这样:
> df <- fread("C:/Users/WZHPCH/Desktop/Error Messages/df.csv", sep=";", stringsAsFactors=FALSE)
> dput(df)
structure(list(ID = c(1L, 2L, 4L, 2L, 3L, 24L), VAL = c("TES+XS0255015603+ae2s",
"TEST*XS0255015603+d2aasd", "safd*adf*XS0255015603++", "gasdfs*dsa*US0917971006",
"asdfsUS0917971006adf", "sd-asd-afds-US0917971006")), .Names = c("ID",
"VAL"), row.names = c(NA, -6L), class = c("data.table", "data.frame"
), .internal.selfref = <pointer: 0x0000000000110788>)
> df$parsedISIN <- gsub("^[a-zA-Z]{2}[0-9]{10}$", '\\1', df$VAL)
我对gsub做错了什么?
任何建议?
感谢您的回复!
3 个答案:
答案 0 :(得分:5)
这里有一些问题:
1)即使问题使用dput,对象中也有一个指针,因此它不能在其他系统上使用。我已经删除了指针给出:
df <-
structure(list(ID = c(1L, 2L, 4L, 2L, 3L, 24L), VAL = c("TES+XS0255015603+ae2s",
"TEST*XS0255015603+d2aasd", "safd*adf*XS0255015603++", "gasdfs*dsa*US0917971006",
"asdfsUS0917971006adf", "sd-asd-afds-US0917971006")), .Names = c("ID",
"VAL"), row.names = c(NA, -6L), class = c("data.table", "data.frame"))
2)代码引用df.gem$Attributes。它应该是df$VAL。
3)gsub应为sub,因为每个组件中只出现一次。
4)匹配仅匹配,如果它从字符串的开头开始并在字符串的结尾处结束,但如果它在字符串中就不匹配,就是这里的情况。
5)要使用sub,我们需要匹配所有内容,只需捕获我们需要的内容,以便排除我们不需要的内容。
试试这个:
pat <- ".*([a-zA-Z]{2}[0-9]{10}).*"
sub(pat, "\\1", df$VAL)
给出:
[1] "XS0255015603" "XS0255015603" "XS0255015603" "US0917971006" "US0917971006"
[6] "US0917971006"
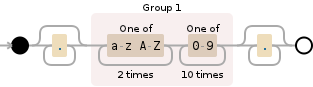
以下是正则表达式pat的可视化:
.*([a-zA-Z]{2}[0-9]{10}).*
注意:更简单的方法是在gsubfn中使用strapplyc直接提取模式。在这种情况下,正则表达式略有简化:
library(gsubfn)
strapplyc(df$VAL, "[a-zA-Z]{2}[0-9]{10}", simplify = TRUE)
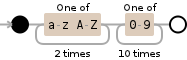
这是一个可视化:
[a-zA-Z]{2}[0-9]{10}
答案 1 :(得分:4)
您只能使用str_extract和一个好的ISIN正则表达式提取ISIN:
library(stringr)
VAL <- c("TES+XS0255015603+ae2s",
"TEST*XS0255015603+d2aasd", "safd*adf*XS0255015603++", "gasdfs*dsa*US0917971006",
"asdfsUS0917971006adf", "steve", "sd-asd-afds-US0917971006")
isin_pat <- "(BE|BM|FR|BG|VE|DK|HR|DE|JP|HU|HK|JO|BR|XS|FI|GR|IS|RU|LB|PT|NO|TW|UA|TR|LK|LV|LU|TH|NL|PK|PH|RO|EG|PL|AA|CH|CN|CL|EE|CA|IR|IT|ZA|CZ|CY|AR|AU|AT|IN|CS|CR|IE|ID|ES|PE|TN|PA|SG|IL|US|MX|SK|KR|SI|KW|MY|MO|SE|GB|GG|KY|JE|VG|NG|SA|MU)([0-9A-Z]{9})([0-9])"
str_extract(VAL, pat)
## [1] "XS0255015603" "XS0255015603" "XS0255015603" "US0917971006"
## [5] "US0917971006" NA "US0917971006"
(我在那里添加了"steve"只是为了显示它什么都没找到时返回的内容。
ISIN代码也需要/应该进行验证(即校验位),除非您完全确定从提取中获得有效的代码。
将其分配到数据框列:
df <- str_extract(VAL, pat)
答案 2 :(得分:2)
基本上,如果您在gsub中继续替换,则需要在要分离的组中添加括号:
> df
ID VAL
1: 1 TES+XS0255015603+ae2s
2: 2 TEST*XS0255015603+d2aasd
3: 4 safd*adf*XS0255015603++
4: 2 gasdfs*dsa*US0917971006
5: 3 asdfsUS0917971006adf
6: 24 sd-asd-afds-US0917971006
> df[,isin:=gsub(".*([A-Z]{2}[0-9]+).*","\\1",VAL)]
> df
ID VAL isin
1: 1 TES+XS0255015603+ae2s XS0255015603
2: 2 TEST*XS0255015603+d2aasd XS0255015603
3: 4 safd*adf*XS0255015603++ XS0255015603
4: 2 gasdfs*dsa*US0917971006 US0917971006
5: 3 asdfsUS0917971006adf US0917971006
6: 24 sd-asd-afds-US0917971006 US0917971006
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?