Python仅在特定位置用整数替换整数
嗨我有一个文件,其中包含如下所示的数据。我想要替换A' A'之后出现的整数。 (第四列)2,3,15,25,115,1215与其他整数,我在字典中有它们(键,值)。 ' A'之后的空白数量。范围从0到3。我在python中尝试了str.replace(old,new)方法,但它替换了文件中所有整数的实例。
这是我想在文件中做的替换。
replacements = {2:0,3:5,15:7,25:30,115:120,1215:1220}
Name 1 N ASHA A 2 35 23
Name 2 R MONA A 3 25 56
Name 3 P TERY A 15 23 32
Name 4 Q JACK A 25 56 25
Name 5 D TOM A 115 57 45
Name 3 P SEN A1215 45 56
建议我做一些方法。
3 个答案:
答案 0 :(得分:2)
replacements = {2:0,3:5,15:7,25:30,115:120,1215:1220}
s="""Name 1 N ASHA A 2 35 23
Name 2 R MONA A 3 25 56
Name 3 P TERY A 15 23 32
Name 4 Q JACK A 25 56 25
Name 5 D TOM A 115 57 45
Name 3 P SEN A1215 45 56"""
res = []
for line in s.splitlines():
spl = line.split()
if len(spl) == 8:
ints = map(int,spl[-3:])
res.append(" ".join(spl[:-3]+[str(replacements.get(k, str(k))) for k in ints]))
else:
spl[-3] = spl[-3].replace("A","")
ints = map(int,spl[-3:])
res.append(" ".join(spl[:-3]+["A"]+[str(replacements.get(k, str(k))) for k in ints]))
print(res)
['Name 1 N ASHA A 0 35 23', 'Name 2 R MONA A 5 30 56', 'Name 3 P TERY A 7 23 32', 'Name 4 Q JACK A 30 56 30', 'Name 5 D TOM A 120 57 45', 'Name 3 P SEN A 1220 45 56']
不确定是否要使用数据或将其写入文件,但如果您的文件类似于您的示例,则会替换dict中的数字,如果分割的len不同,我们知道我们有一个数字和一个A没有空格,所以我们更换。
总是会有一个空间,所以如果你写入文件并且必须再次处理该文件,那将会容易得多。
我会删除地图并使用字符串作为键和值,除非你真的想要整数。 如果您想保持完全相同的格式,只想更改第一个数字:
replacements = {"2":"0","3":"5","15":"7","25":"30","115":"120","1215":"1220"}
s="""Name 1 N ASHA A 2 35 23
Name 2 R MONA A 3 25 56
Name 3 P TERY A 15 23 32
Name 4 Q JACK A 25 56 25
Name 5 D TOM A 115 57 45
Name 3 P SEN A1215 45 56"""
res = []
for line in s.splitlines():
spl = line.rsplit(None, 3)
end = spl[-3:]
if "A" == end[0][0]:
k = end[0][1:]
res.append(line.replace(k,replacements.get(k,k)))
else:
k = end[0]
res.append(line.replace(k,replacements.get(k,k)))
print(res)
['Name 1 N ASHA A 0 35 03', 'Name 2 R MONA A 5 25 56', 'Name 3 P TERY A 7 23 32', 'Name 4 Q JACK A 30 56 30', 'Name 5 D TOM A 120 57 45', 'Name 3 P SEN A1220 45 56']
答案 1 :(得分:1)
Regex101
^[\w\d\s]{23}([\d\s]{1,4}).*$
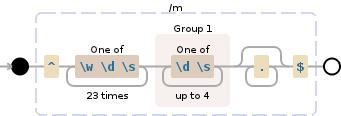
注意:这更像是一个固定长度的解析
的Python
import re
replacements = {2:0,3:5,15:7,25:30,115:120,1215:1220}
searchString = "Name 1 N ASHA A 2 35 23 "
replace_search = re.search('^[\w\d\s]{23}([\d\s]{1,4}).*$', searchString, re.IGNORECASE)
if replace_search:
result = replace_search.group(1)
convert_result = int(result)
dictionary_lookup = int(replacements[convert_result])
replace_result = '% 4d' % dictionary_lookup
regex_replace = r"\g<1>" + replace_result + r"\g<3>"
line = re.sub(r"^([\w\d\s]{23})([\d\s]{1,4})(.*)$", regex_replace, searchString)
print(line)
答案 2 :(得分:1)
根据有关所有其他数字的其他信息进行编辑。
这完全取决于您在评论中提到的文件的特定特征。
replacements = {2:0,3:5,15:7,25:30,115:120,1215:1220}
with open('input.txt', 'r') as fin, open('output.txt', 'w') as fout:
pos_a = 22 # 0-indexed position of 'A' in every line
for line in fin:
left_side = line[:pos_a + 1]
num_to_convert = line[pos_a + 1: pos_a + 5]
right_side = line[pos_a + 5:]
# String formatting to preserve padding as per original file
newline = '{}{:>4}{}'.format(left_side,
replacements[int(num_to_convert)],
right_side)
fout.write(newline)
如果列中的某个值可能不在您的replacements字典中,并且您希望保持该值不变,那么请replacements[int(num1)]代替replacements.get(int(num1), num1)而不是{{1}} }
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?