жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе’ҢжӣҝжҚўR
жҲ‘жӯЈеңЁе°қиҜ•зј–еҶҷдёҖдёӘжӯЈеҲҷиЎЁиҫҫејҸпјҢз”ЁйҖ—еҸ·д№ӢеүҚе’Ңд№ӢеҗҺзҡ„第дёҖдёӘеҶ’еҸ·д№ӢеҗҺзҡ„дёӨдёӘж•°еӯ—жӣҝжҚўжӯӨзҹ©йҳөдёӯзҡ„жҜҸдёӘе…ғзҙ гҖӮиҝҳжңүвҖң./гҖӮпјҡгҖӮпјҡгҖӮпјҡгҖӮпјҡгҖӮвҖқжҲ‘жғіж”№дёәвҖң0,0вҖқгҖӮ
head(data)
Offspring-95_CAATCG Offspring-96_AAACGG Offspring-97_ACTCTT
[1,] "./.:1,7:8:18:262,0,18" "0/1:18,4:21:56:56,0,591" "0/0:27,0:27:78:0,78,723"
[2,] "0/0:49,0:49:99:0,147,1891" "0/0:107,0:107:99:0,319,4185" "1/1:0,22:22:66:902,66,0"
[3,] "0/0:42,0:42:99:0,126,1324" "./.:.:.:.:." "0/1:35,88:117:99:3152,0,718"
жҲ‘иҜ•иҝҮдәҶпјҡ
try <- gsub("\\:[0-9]*\\,[0-9]*\\:", \\1, data)
жүҖйңҖзҡ„иҫ“еҮәжҳҜпјҡ
Offspring-95_CAATCG Offspring-96_AAACGG Offspring-97_ACTCTT
[1,] "1,7" "18,4" "27,0"
[2,] "49,0" "107,0" "0,22"
[3,] "42,0" "0,0" "35,88"
и°ўи°ўпјҢ
3 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ2)
иҝҷеҸҜд»ҘйҖҡиҝҮ
жқҘе®ҢжҲҗ sub('[^:]+:([^:]+).*', '\\1', data)
# Offspring.95_CAATCG Offspring.96_AAACGG Offspring.97_ACTCTT
#[1,] "1,7" "18,4" "27,0"
#[2,] "49,0" "107,0" "0,22"
#[3,] "9,4" "33,13" "13,0"
еҸҜи§ҶеҢ–
[^:]+:([^:]+).*
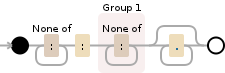
жҲ–дҪҝз”Ёregmatches
base R
data[] <- regmatches(data, regexpr('(?<=:)[0-9]+,[0-9]+', data, perl=TRUE))
еҸҜи§ҶеҢ–
(?<=:)[0-9]+,[0-9]+
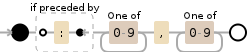
д»ҘдёҠregexеҸҜдёҺstringrжҲ–stringiдёҖиө·дҪҝз”ЁпјҲйҖӮз”ЁдәҺеӨ§ж•°жҚ®йӣҶпјү
library(stringr)
`dim<-`(str_extract(data, perl('(?<=:)[0-9]+,[0-9]+')), dim(data))
# [,1] [,2] [,3]
#[1,] "1,7" "18,4" "27,0"
#[2,] "49,0" "107,0" "0,22"
#[3,] "9,4" "33,13" "13,0"
жҲ–иҖ…
library(stringi)
`dim<-`(stri_extract(data, regex='(?<=:)[0-9]+,[0-9]+'), dim(data))
# [,1] [,2] [,3]
#[1,] "1,7" "18,4" "27,0"
#[2,] "49,0" "107,0" "0,22"
#[3,] "9,4" "33,13" "13,0"
жӣҙж–°
data1[] <- sub('[^:]+:([^:]+).*', '\\1', data1)
data1[!grepl(',', data1)] <- '0,0'
data1
# Offspring.95_CAATCG Offspring.96_AAACGG Offspring.97_ACTCTT
#[1,] "1,7" "18,4" "27,0"
#[2,] "49,0" "107,0" "0,22"
#[3,] "42,0" "0,0" "35,88"
ж•°жҚ®
data <- structure(c("./.:1,7:8:18:262,0,18", "0/0:49,0:49:99:0,147,1891",
"0/1:9,4:13:99:129,0,334", "0/1:18,4:21:56:56,0,591",
"0/0:107,0:107:99:0,319,4185",
"0/1:33,13:44:99:317,0,1150", "0/0:27,0:27:78:0,78,723",
"1/1:0,22:22:66:902,66,0", "0/0:13,0:13:39:0,39,528"), .Dim = c(3L, 3L),
.Dimnames = list(NULL, c("Offspring.95_CAATCG", "Offspring.96_AAACGG",
"Offspring.97_ACTCTT")))
data1 <- structure(c("./.:1,7:8:18:262,0,18", "0/0:49,0:49:99:0,147,1891",
"0/0:42,0:42:99:0,126,1324", "0/1:18,4:21:56:56,0,591",
"0/0:107,0:107:99:0,319,4185",
"./.:.:.:.:.", "0/0:27,0:27:78:0,78,723", "1/1:0,22:22:66:902,66,0",
"0/1:35,88:117:99:3152,0,718"), .Dim = c(3L, 3L), .Dimnames = list(
NULL, c("Offspring.95_CAATCG", "Offspring.96_AAACGG", "Offspring.97_ACTCTT"
)))
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ1)
дёҚжҳҜжӯЈеҲҷиЎЁиҫҫејҸпјҢдҪҶеҸҜиғҪйқһеёёеҝ«гҖӮ
apply(data, 2, function(x) sapply(strsplit(x, ":"), "[[", 2))
## Offspring.95_CAATCG Offspring.96_AAACGG Offspring.97_ACTCTT
## [1,] "1,7" "18,4" "27,0"
## [2,] "49,0" "107,0" "0,22"
## [3,] "9,4" "33,13" "13,0"
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ0)
иҜ•иҜ•иҝҷдёӘпјҡ
out<-list()
for(i in seq(ncol(data)))
out[[i]]<-gsub('[^:]*:([0-9]+,[0-9]+).*','\\1',data[,i])
out<-as.data.frame(out)
dimnames(out)<-dimnames(data)
out
зӣёе…ій—®йўҳ
- жӯЈеҲҷиЎЁиҫҫејҸжӣҝжҚў
- RжӯЈеҲҷиЎЁиҫҫејҸпјҡhttpеҢ№й…Қ
- жӯЈеҲҷиЎЁиҫҫејҸ - иҙӘеҝғеҢ№й…Қпјҹ
- жӯЈеҲҷиЎЁиҫҫејҸ - жӣҝжҚў$е’Ң^
- еҢ№й…ҚRдёӯзҡ„жӯЈеҲҷиЎЁиҫҫејҸ
- жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе’ҢжӣҝжҚўR
- жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қе’ҢжӣҝжҚўpvalueеӯ—з¬ҰдёІ
- дҪҝз”ЁgreplжӣҝжҚўи§ЈжһҗжӯЈеҲҷиЎЁиҫҫејҸ
- жӯЈеҲҷиЎЁиҫҫејҸпјҡеҢ№й…ҚеӨҡдёӘеҚ•иҜҚ
- еңЁеӯ—з¬ҰдёІжӣҝжҚўдёӯдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸ
жңҖж–°й—®йўҳ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ