在Python正则表达式中循环使用组
我有这个Python正则表达式,它处理我必须解析的大多数字符串。
edge_value_pattern = re.compile(r'(?P<edge>e[0-9]+) +(?P<label1>[^ ]*)[^"]+"(?P<word>[^"]+)"[^:]+:: (?P<label2>[^\n]+)')
这是我的正则表达式要解析的示例字符串:
'e0 BIKE-EVENT 1 "biking" 2'
它正确地将e0存储到edge组中,将BIKE-EVENT正确存储到label1组中,将"biking"存储到word组中。最后一组label2用于字符串的略有不同的变体,如下所示。请注意,label2正则表达式组在给定类似下面的字符串时表现如预期。
'e29 e30 "of" :: of, OF'
然而,正则表达式模式填充label1的值e30.事实是此字符串没有任何label1值 - 它应该是None或至少空字符串。 ad-hoc解决方案是使用正则表达式解析label1以确定它是实际标签还是只是另一个边缘。我想知道是否有办法修改我的原始正则表达式,以便小组edge接收所有edges。例如,上述字符串的输出为:
edge = "e29 e30"
label1 = None
word = of
label2 = of, OF
我在下面尝试了这个解决方案,我认为这可以转换为简单地循环遍历第一个组edge(如果我有一个实际的FSA,这将是微不足道的),但它不会改变行为正则表达式。
edge_value_pattern = re.compile(r'(?P<edge>(e[0-9]+)+) +(?P<label1>[^ ]*)[^"]+"(?P<word>[^"]+)"[^:]+:: (?P<label2>[^\n]+)')
1 个答案:
答案 0 :(得分:0)
如果您希望edge与"e29 e30"匹配,则必须将重复放在组中,而不是在外面。
你是通过在edge组中添加一个+重复的新组来做到这一点 - 这很好,虽然你可能想要一个非捕获组 - 但你忘了包含空间在重复小组里面。
(你也离开了外部重复,并使用了一个你可能想要非捕获的捕获组,但那些不太严重。)
只看那个片段:
(?P<edge>(e[0-9]+)+)
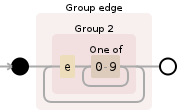
此处,表达式将e29作为一个匹配,然后e30作为后续匹配。因此,如果您在表达式中添加任何其他内容,则可能会错过e29,或者只是失败。但是添加空格:
(?P<edge>(e[0-9]+ )+)

现在它匹配e29 e30加上尾随空格作为单个匹配,这意味着你可以使用任何额外的东西并且它可以工作(只要你得到正确的其他东西 - 你仍然需要删除额外的+,我认为你可能需要做一些非贪婪的重复......)。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?