python 3.4将文本文件过滤到列表中
我在将.txt文件过滤到子列表时遇到了一些麻烦,然后我可以将其转换为目录。
来自text.txt的样本
A2.-B4-...C4-.-.D3-..E1.F4..-.G3--.H4....75--...85---..95----.05-----.6.-.-.-,6--..--?6..--..!5..--.
没有空格或换行符,它基本上是一行文字。
A2.-表示符号'A'有2个字符在莫尔斯码中,它们是.-等等
我想做的是将这个长字符串分成子列表,然后我可以将它们压缩到一个目录中,然后我可以用它来制作莫尔斯电码翻译。我希望程序做什么:创建一个列表keyList,其中包含键A,B,C,...,?,。,
和另一个列表valueList,其中包含键的值。
但是,因为密钥不是所有字母,所以在过滤整个文件时都存在问题。
我的尝试:
import re
r = open("text.txt", "r")
ss = r.read()
p = re.compile('\w'+'\w')
keyList = p.findall(ss)
ValueList = p.split(ss)
print(keyList)
print(ValueList)
keyList = ['A2', 'B4', 'C4', 'D3',..., '75', '85', '95', '05']
ValueList = ['', '.-', '-...', '-.-.', '-..', space , !5..--.']
如上所示,值列表不会正确分割,因为'\ w'+'\ w'只会匹配字母数字字符..我已经尝试更改re.compile上的参数但是没有找到任何有效的参数。有帮助吗?是重新编译了最好的方法,还是有另一种方法可以过滤文本?
编辑:预期/想要的输出:
keyList = ['A','B','C','D',...,'.','?',',']
ValueList = ['.-','-...','-.-.','-..',...,'.-.-.-','..--..','--..--']
4 个答案:
答案 0 :(得分:1)
要制作编码器/解码器,您可能希望使用词典而不是列表。
就解析它而言,直接天真的方法可能最好。
result = {}
with open('morse.txt', 'r') as f:
while True:
key = f.read(1)
length_str = f.read(1)
if len(key) != 1 or len(length_str) != 1:
break
try:
length = int(length_str)
except ValueError:
break
value = f.read(length)
if len(value) == length:
result[key] = value
for k, v in result.items():
print k, v
结果:
A .-
! ..--.
C -.-.
B -...
E .
D -..
G --.
F ..-.
H ....
, --..--
. .-.-.-
0 -----
7 --...
9 ----.
8 ---..
? ..--..
答案 1 :(得分:1)
您可以尝试以下操作:
items = re.findall(r'(.\d)([\.-]+)', ss)
keys = [s[0][0] for s in items]
values = [s[1] for s in items]
我得到了:
>>> keys
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', '7', '8', '9', '0', ',', '?', '!']
values
['.-', '-...', '-.-.', '-..', '.', '..-.', '--.', '....', '--...', '---..', '----.', '-----.', '--..--', '..--..', '..--.']
答案 2 :(得分:0)
与Cuadue's answer类似,我会使用循环来解析它,但我会以相反的顺序执行此操作:
morse_str = 'A2.-B4-...C4-.-.D3-..E1.F4..-.G3--.H4....75--...85---..95----.05-----.6.-.-.-,6--..--?6..--..!5..--.'
morse_list = list(morse_str)
morse_dict = {}
while morse_list:
morse = ''
while True:
sym = morse_list.pop()
try:
int(sym)
except ValueError:
morse += sym
else:
key = morse_list.pop()
morse_dict[key] = morse[::-1]
break
答案 3 :(得分:0)
要查找可在正则表达式中使用positive look-ahead的键:
>>> s = 'A2.-B4-...C4-.-.D3-..E1.F4..-.G3--.H4....75--...85---..95----.05-----.6.-.-.-,6--..--?6..--..!5..--.'
>>> keys = re.findall(r'[\w|\W](?=\d\W)',s)
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', '7', '8', '9', '0', '.', ',', '?', '!']
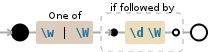
由于您的密钥和值都没有!和,.之类的字母字符,因此您无法使用jut one re函数来获取预期值,可以使用带有split()函数的模式根据您的键分割字符串,这样您就可以在前导处输出只有一位数的预期值,然后使用re.sub()删除该数字:
>>> values = [re.sub('\d','',i) for i in re.split(r'[\w|\W](?=\d)',s) if len(i)]
['.-', '-...', '-.-.', '-..', '.', '..-.', '--.', '...', '--..', '---.', '----', '-----', '.-.-.-', '--..--', '..--..', '..--.']
因此,对于len和keys,您必须具有相同values的重要事项:
>>> len(keys)
16
>>> len(values)
16
最后压缩它们:
>>> dict(zip(keys,values))
{'A': '.-', '!': '..--.', 'C': '-.-.', 'B': '-...', 'E': '.', 'D': '-..', 'G': '--.', 'F': '..-.', 'H': '...', ',': '--..--', '.': '.-.-.-', '0': '-----', '7': '--..', '9': '----', '8': '---.', '?': '..--..'}
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?