windbg!堆输出中'size'数字的含义是什么?
我在DMP文件中看到这样的输出:
Heap entries for Segment00 in Heap 00150000
00150640: 00640 . 00040 [01] - busy (40)
00150680: 00040 . 01808 [01] - busy (1800)
00151e88: 01808 . 00210 [01] - busy (208)
00152098: 00210 . 00228 [00]
001522c0: 00228 . 00030 [01] - busy (22)
001522f0: 00030 . 00018 [01] - busy (10)
00152308: 00018 . 00048 [01] - busy (3c)
WinDbg文档说:
Heap entries for Segment00 in Heap 250000
0x01 - HEAP_ENTRY_BUSY
0x02 - HEAP_ENTRY_EXTRA_PRESENT
0x04 - HEAP_ENTRY_FILL_PATTERN
0x08 - HEAP_ENTRY_VIRTUAL_ALLOC
0x10 - HEAP_ENTRY_LAST_ENTRY
0x20 - HEAP_ENTRY_SETTABLE_FLAG1
0x40 - HEAP_ENTRY_SETTABLE_FLAG2
Entry Prev Cur 0x80 - HEAP_ENTRY_SETTABLE_FLAG3
Address Size Size flags (Bytes used) (Tag name)
00250000: 00000 . 00b90 [01] - busy (b90)
00250b90: 00b90 . 00038 [01] - busy (38)
00250bc8: 00038 . 00040 [07] - busy (24), tail fill (NTDLL!LDR Database)
虽然文档中的间距很奇怪。这是指“入境地址”和“上限大小”和“大小”,还是“条目”'上限'和'下限'不适用于以下行?
'prev size'和'cur size'是什么意思?特别是关于'使用的字节'。 '使用的字节'和'cur size'之间有什么区别?
1 个答案:
答案 0 :(得分:6)
堆段是给定堆的连续内存块。它也是一堆堆条目。
要向前遍历堆条目列表,我们可以使用Cur Size作为偏移量来到达下一个堆条目。
要向后遍历堆条目列表,我们可以使用Prev Size作为偏移量来到达上一个条目的开头。
在这里(下图)你可以看到psize(之前的大小)及其与前一个条目的大小(当前大小)的关系。
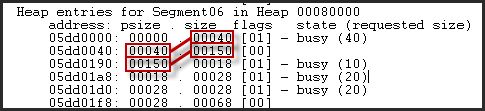
使用的字节数是通过从该块末尾未实际分配的未使用字节数中减去大小来计算的。这允许您在将请求的大小四舍五入到分配粒度之前确定所请求的分配大小。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?