Python:使用字典,在另一个文本文件中搜索字符串并打印整行
如果其中一个单词位于第二个txt文件中,我想从字典中搜索。 我有以下代码的问题:
print 'Searching for known strings...\n'
with open('something.txt') as f:
haystack = f.read()
with open('d:\\Users\\something\\Desktop\\something\\dictionary\\entirelist.txt') as f:
for needle in (line.strip() for line in f):
if needle in haystack:
print line
公开声明不是来自我,我是从以下来的: Python: search for strings listed in one file from another text file? 我想打印这条线,所以我写了一行而不是针。问题来了:它说"线没有定义"。
我的最终目标是查看词典中的任何单词是否在" something.txt"中,如果是,则打印单词被识别的行。 对不起英语不好或致敬,希望你能帮助我! 谢谢你的理解:)
2 个答案:
答案 0 :(得分:0)
看起来你已经使用了一个生成器:( line.strip()用于f中的行),我不认为你可以访问内部变量' line'从发电机范围外,即在支架外。
尝试类似:
for line in f:
if line.strip() in haystack:
print line
答案 1 :(得分:0)
您询问的具体例外是因为line不存在于生成器表达式之外。如果要访问它,则需要将其与print语句保持在同一范围内,如下所示:
for line in f:
needle = line.strip()
if needle in haystack:
print line
但这并不是特别有用。它只是来自needle的字加上最后的换行符。如果您要打印haystack包含needle的行(或行?),则必须搜索该行,而不仅仅是询问needle是否出现在整个haystack中{ {1}}。
要完全按照您的要求执行操作,您需要遍历haystack的行并检查每个needle。像这样:
with open('something.txt') as f:
haystacks = list(f)
with open('d:\\Users\\something\\Desktop\\something\\dictionary\\entirelist.txt') as f:
for line in f:
needle = line.strip()
for haystack in haystacks:
if needle in haystack:
print haystack
但是,您可能需要考虑一个巧妙的技巧:如果您可以编写与包含needle的任何完整行匹配的正则表达式,那么您只需要打印出所有匹配项。像这样:
with open('something.txt') as f:
haystack = f.read()
with open('d:\\Users\\something\\Desktop\\something\\dictionary\\entirelist.txt') as f:
for line in f:
needle = line.strip()
pattern = '^.*{}.*$'.format(re.escape(needle))
for match in re.finditer(pattern, haystack, re.MULTILINE):
print match.group(0)
以下是正则表达式如何工作的示例:
^.*Falco.*$
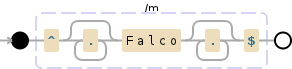
当然,如果你想要不区分大小写搜索,或者只搜索完整的单词等,你需要做一些小改动;请参阅Regular Expression HOWTO或第三方教程了解更多信息。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?