使用python从文本文件解析IP地址/网络
我有以下文本文件,我需要一些解析IP地址的帮助。
文本文件的格式为
abc 10.1.1.1/32 aabbcc
def 11.2.0.0/16 eeffgg
efg 0.0.0.0/0 ddeeff
换句话说,一堆IP网络作为日志文件的一部分存在。输出应如下所示:
10.1.1.1/32
11.2.0.0/16
0.0.0.0/0
我有以下代码但不输出所需信息
file = open(filename, 'r')
for eachline in file.readlines():
ip_regex = re.findall(r'(?:\d{1,3}\.){3}\d{1,3}', eachline)
print ip_regex
2 个答案:
答案 0 :(得分:5)
首先,你的正则表达式甚至不会尝试捕获除了四个虚线数字之外的任何东西,所以当然它不会与其他任何东西匹配,就像最后的/32一样。如果您只是将/\d{1,2}添加到最后,它会解决这个问题:
(?:\d{1,3}\.){3}\d{1,3}/\d{1,2}
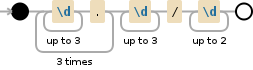
但是,如果你不能很好地理解正则表达式,那么你可能不应该使用正则表达式作为一个"魔法"你永远无法调试或扩展。对于str或split等find方法,它有点冗长,但对于新手来说可能更容易理解:
for line in file:
for part in line.split()
try:
address, network = part.split('/')
a, b, c, d = address.split('.')
except ValueError:
pass # not in the right format
else:
# do something with part, or address and network, or whatever
作为旁注,根据您对这些事情的实际操作,您可能希望使用ipaddress模块(或the backport on PyPI用于2.6-3.2)而不是字符串解析:
>>> import ipaddress
>>> s = '10.1.1.1/32'
>>> a = ipaddress.ip_network('10.1.1.1/32')
您可以将其与上述任何一项结合使用:
for line in file:
for part in line.split():
try:
a = ipaddress.ip_network(part)
except ValueError:
pass # not the right format
else:
# do something with a and its nifty methods
答案 1 :(得分:1)
在这种特殊情况下,正则表达式可能过度,您可以使用split
with open(filename) as f:
ipList = [line.split()[1] for line in f]
这应该产生一个字符串列表,即IP地址。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?