正则表达式时段匹配所有内容减去最后一个字符
我的正则表达式代码如下:
(.(?!\[view street map\]))+
这是为了匹配[查看街道地图]之前的所有内容。
但是如果我在下面的
中使用这个正则表达式代码Test of the system[view street map]
匹配以下内容,并切断最后一个字符
Test of the syste
任何人都知道为什么会这样?
提前致谢!
4 个答案:
答案 0 :(得分:2)
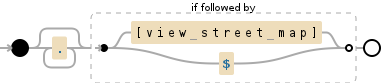
您必须添加一个起始锚点以匹配所有内容,直到[view street map]如果该特定行上出现[view street map]。如果[view street map]不存在则匹配整行。
^(?:(?!\[view street map\]).)+
<强>解释
-
^锚点,表示一行的开头。 -
(?:..)被称为非捕获组。 -
(?:(?!\[view street map\]).)在正则表达式引擎匹配第一个字符之前,它检查边界后面的字符串是否为[view street map]。如果它是[view street map],那么它将无法匹配。如果它不是[view street map],那么只有它匹配第一个字符。如果我们在整个非捕获组之后添加+,则regex引擎将从一开始就为每个字符执行上述步骤(不仅仅用于第一个字符)。+重复前一个令牌一次或多次。
答案 1 :(得分:2)
您应该在使用角色之前进行检查:
^((?!\[view street map\]).)+
消耗然后检查不允许的字符串是否也错误地匹配字符串“[view street map]”。
我忘记了在之前版本中的锚定。我们需要确保匹配从字符串的开头开始,或者当引擎在下一个索引处重试匹配时可以绕过检查。
答案 2 :(得分:0)
(.(?!\[view street map\]))+基本上是说匹配一个字符并检查[view street map]是否提前。 m已提前[view street map]。所以它失败了。其余的都过去了。
您可以尝试:
\[view street map\]|(.)
抓取捕获并将它们连接在一起以获取字符串。请参阅demo。
或尝试
\[view street map\]
替换为空字符串。请参阅demo。
答案 3 :(得分:0)
您当前的逻辑 - 逐个采用所有符号,每个符号后面跟[view street map]。您可以将逻辑更改为以下内容 - 将符号批处理后跟[view street map]或end-of-string。
.*?(?=(?:\[view street map\])|$)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?