正则表达式以找到最小可能匹配
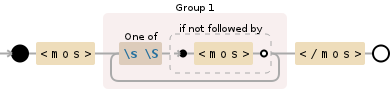
我使用JavaScript正则表达式/(<mos>[\s\S]*?<\/mos>)/g在日志文件中查找大致如下所示的XML块:
Entry 1: <mos>...</mos>
Entry 2: <mos>...</mos>
但是,有时日志记录过程遇到错误并且没有完成向文件写入条目,在这种情况下它看起来像这样:
Entry 1: <mos>Error!
Entry 2: <mos>...</mos>
当发生这种情况时,正则表达式匹配从条目1中的开始<mos>标记到条目2中的结束</mos>标记的所有内容,这会在以后处理XML时导致问题。
似乎以某种方式首先匹配结束标记然后回顾它们相应的开始标记会避免这种情况,但我不知道如何做到这一点,或者是否可以使用正则表达式。
澄清:由起始标记和结束标记分隔的块中的...可以包含换行符。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?