如何在MATLAB中使用REGEXP选择字符串的一部分或另一部分
我一直试图在最近几天解决这个问题但没有成功。我有以下字符串:
comment = '#disabled, Fc = 200Hz'
我需要做的是:如果有字符串'disabled'则需要匹配。否则,我需要匹配'Hz'之前的数字。
我到目前为止找到的最接近的解决方案是:
regexpi(comment,'\<#disabled\>|\w*Hz\>','match') ;
它会匹配单词'#disabled'或'Hz'之前的任何内容。问题是,当它第一次找到'#disabled#'时,它也会复制结果'200Hz'。
所以我得到了:
ans = '#disabled' '200Hz'
总结一下,我需要只选择一个字符串的'disabled'部分,否则我需要在'Hz'之前得到该数字。
有人可以帮我一把吗?
1 个答案:
答案 0 :(得分:5)
假设您的输入是:
comment = {'#disabled, Fc = 200Hz';
'Fc = 300Hz'}
正则表达式(如果跟随#,则匹配禁用,否则匹配数字,如果它们后跟Hz):
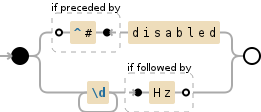
regexp(comment, '(?<=^#)disabled|\d+(?=Hz)','match','once')
解释:
-
^#- 在该行的开头匹配# -
(?<=expr)disabled- 匹配disabled如果跟随expr -
expr1 | expr2- 否则匹配expr2 -
\d+- 匹配1位或更多位数,相当于[0-9]+ -
expr(?=Hz)- 仅在expr后跟
'Hz'匹配
图:
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?