如何使用ggplot2中的多个变量更好地创建堆积条形图?
我经常需要制作堆积的条形图来比较变量,因为我在R中完成所有的统计数据,所以我更喜欢使用ggplot2来完成R中的所有图形。我想学习如何做两件事:
首先,我希望能够为每个变量添加适当的百分比刻度标记,而不是按计数添加刻度标记。计数会让人感到困惑,这就是我完全取出轴标签的原因。
其次,必须有一种更简单的方法来重新组织我的数据以实现这一目标。看起来我应该能够在ggplot2中使用plyR进行本地操作,但是plyR的文档不是很清楚(我已经阅读了ggplot2书籍和在线plyR文档。
我的最佳图表如下所示,创建它的代码如下:
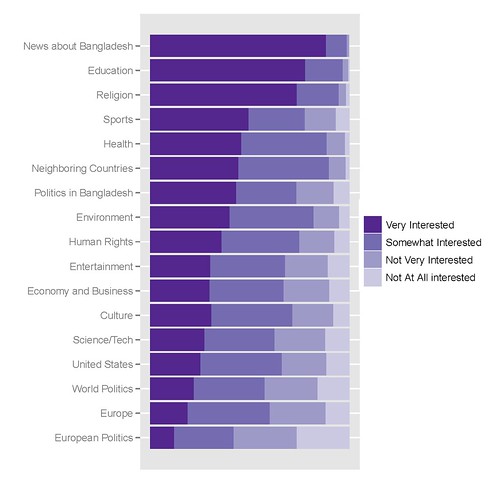
我用来获取它的R代码如下:
library(epicalc)
### recode the variables to factors ###
recode(c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ), c(1,2,3,4,5,6,7,8,9, NA),
c('Very Interested','Somewhat Interested','Not Very Interested','Not At All interested',NA,NA,NA,NA,NA,NA))
### Combine recoded variables to a common vector
Interest1<-c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ)
### Create a second vector to label the first vector by original variable ###
a1<-rep("News about Bangladesh", length(int_newcoun))
a2<-rep("Neighboring Countries", length(int_newneigh))
[...]
a17<-rep("Education", length(int_educ))
Interest2<-c(a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, a16, a17)
### Create a Weighting vector of the proper length ###
Interest.weight<-rep(weight, 17)
### Make and save a new data frame from the three vectors ###
Interest.df<-cbind(Interest1, Interest2, Interest.weight)
Interest.df<-as.data.frame(Interest.df)
write.csv(Interest.df, 'C:\\Documents and Settings\\[name]\\Desktop\\Sweave\\InterestBangladesh.csv')
### Sort the factor levels to display properly ###
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Not Very Interested')
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Somewhat Interested')
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Very Interested')
Interest.df$Interest2<-relevel(Interest$Interest2, ref='News about Bangladesh')
Interest.df$Interest2<-relevel(Interest$Interest2, ref='Education')
[...]
Interest.df$Interest2<-relevel(Interest$Interest2, ref='European Politics')
detach(Interest)
attach(Interest)
### Finally create the graph in ggplot2 ###
library(ggplot2)
p<-ggplot(Interest, aes(Interest2, ..count..))
p<-p+geom_bar((aes(weight=Interest.weight, fill=Interest1)))
p<-p+coord_flip()
p<-p+scale_y_continuous("", breaks=NA)
p<-p+scale_fill_manual(value = rev(brewer.pal(5, "Purples")))
p
update_labels(p, list(fill='', x='', y=''))
我非常感谢任何提示,技巧或提示。
5 个答案:
答案 0 :(得分:2)
您不需要prop.tables或计数等来执行100%堆叠条形图。您只需要+geom_bar(position="stack")
答案 1 :(得分:2)
你的第二个问题可以通过重塑包装中的熔化和铸造来解决
在对data.frame中的元素进行因素分析后,您可以使用以下内容:
install.packages("reshape")
library(reshape)
x <- melt(your.df, c()) ## Assume you have some kind of data.frame of all factors
x <- na.omit(x) ## Be careful, sometimes removing NA can mess with your frequency calculations
x <- cast(x, variable + value ~., length)
colnames(x) <- c("variable","value","freq")
## Presto!
ggplot(x, aes(variable, freq, fill = value)) + geom_bar(position = "fill") + coord_flip() + scale_y_continuous("", formatter="percent")
顺便说一句,我喜欢使用grep从凌乱的导入中提取列。例如:
x <- your.df[,grep("int.",df)] ## pulls all columns starting with "int_"
当您不必输入c('',...)一百万次时,分解会更容易。
for(x in 1:ncol(x)) {
df[,x] <- factor(df[,x], labels = strsplit('
Very Interested
Somewhat Interested
Not Very Interested
Not At All interested
NA
NA
NA
NA
NA
NA
', '\n')[[1]][-1]
}
答案 2 :(得分:1)
关于..count..的百分比,请尝试:
ggplot(mtcars, aes(factor(cyl), prop.table(..count..) * 100)) + geom_bar()
但由于将函数推送到aes()并不是一个好主意,因此您可以编写自定义函数来创建..count..之外的百分比,将其四舍五入到n小数等。< / p>
您使用plyr标记了此帖子,但我在此处看不到任何plyr,我敢打赌,ddply()可以完成这项工作。在线plyr文档就足够了。
答案 3 :(得分:1)
如果我理解正确,要解决轴标签问题,请进行以下更改:
# p<-ggplot(Interest, aes(Interest2, ..count..))
p<-ggplot(Interest, aes(Interest2, ..density..))
至于第二个,我认为你最好不要使用reshape package。您可以使用它轻松地将数据聚合到组中。
参考下面的aL3xa评论......
library(ggplot2)
r<-rnorm(1000)
d<-as.data.frame(cbind(r,1:1000))
ggplot(d,aes(r,..density..))+geom_bar()
...返回
alt text http://www.drewconway.com/zia/wp-content/uploads/2010/04/density.png
{kind=link}
这些垃圾箱现在是密度......
答案 4 :(得分:1)
你的第一个问题:这会有帮助吗?
geom_bar(aes(y=..count../sum(..count..)))
你的第二个问题;你可以使用重新排序来排序吧?像
这样的东西aes(reorder(Interest, Value, mean), Value)
(刚从七小时车程回来 - 累了 - 但我想它应该有用)
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?