递归和迭代
有什么区别?这些都一样吗?如果没有,有人可以举个例子吗?
MW: 迭代-1:迭代或重复的动作或过程:作为:一个过程,其中一系列操作的重复产生连续接近期望结果的结果b:一系列计算机指令的重复指定次数或直到满足条件
Recusion - 3:一种计算机编程技术,涉及使用一个或多次调用自身的过程,子程序,函数或算法,直到满足指定条件,此时每次重复的其余部分从最后一次处理一个叫到第一个
7 个答案:
答案 0 :(得分:8)
我们可以从recursive and iterative processes区分(如在SICP中所做的)递归和迭代过程。前者如您的定义所述,其中递归与数学recursion基本相同:recursive procedure是根据其自身定义的。迭代过程使用循环语句重复代码块。然而,递归过程是一个非常量(例如O(n) or O(lg(n)) space)执行的过程,而迭代过程则需要O(1)(常量)空间。
对于数学例子,Fibonacci数是递归定义的:

Sigma notation类似于迭代:
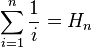
Pi notation。类似于一些(数学)递归公式可以被重写为迭代公式,一些(但不是全部)递归过程具有迭代等价物。通过跟踪您自己的数据结构中的部分结果,而不是使用函数调用堆栈,可以将所有递归过程转换为迭代过程。
答案 1 :(得分:2)
根据您提到的定义,这两个是非常不同的。在迭代中,没有自调用,但在递归中,函数调用自身
例如。因子计算的迭代算法
fact=1
For count=1 to n
fact=fact*count
end for
递归版
function factorial(n)
if (n==1) return 1
else
n=n*factorial(n-1)
end if
end function
一般
递归代码更简洁但使用更大量的内存。有时递归可以使用dynamic programming.
转换为迭代答案 2 :(得分:2)
[快点并特朗普!]
一个表单可以转换为另一个表单,但有一个值得注意的限制:许多“流行”语言(C / Java /普通Python)不支持TCO / TCE(尾部调用优化/每次方法以递归方式调用自身时,使用递归将“向堆栈中添加额外的数据”。
所以在C和Java中,迭代是惯用的,而在Scheme或Haskell中,递归是惯用的。
答案 3 :(得分:1)
这是一个用于查找列表长度的Lisp函数。这是递归的:
(defun recursive-list-length (L)
"A recursive implementation of list-length."
(if (null L)
0
(1+ (recursive-list-length (rest L)))))
它显示“如果列表为空,则列表的长度为0,或者1加上以第二个元素开头的子列表的长度。”
这是strlen的实现 - C函数查找以空字符结尾的char*字符串的长度。它是迭代的:
size_t strlen(const char *s)
{
size_t n;
n = 0;
while (*s++)
n++;
return(n);
}
你的目标是重复一些操作。使用迭代,您使用显式循环(如while代码中的strlen循环)。使用递归,您的函数使用(通常)较小的参数调用自身,依此类推,直到满足边界条件(上面代码中的null L)。这也重复了操作,但是没有明确的循环。
答案 4 :(得分:1)
递归: 例如:以斐波纳契系列为例。要获得任何斐波纳契数,我们必须知道前一个。因此,你将对每个数字的操作(同一个)进行操作(同一个),并且每次调用相同的方法。
fib(5)= Fib(4)+ 5
fib(4)= Fib(3)+4 。 。 即重用方法fib
迭代循环就像你加上1 + 1 + 1 + 1 + 1(迭代加法)得到5或3 * 3 * 3 * 3 * 3(迭代乘法)得到3 ^ 5。
答案 5 :(得分:0)
对于上述的一个很好的例子,考虑用于深度优先搜索的递归v。迭代过程。它可以通过递归函数调用使用语言功能完成,也可以使用堆栈在迭代循环中完成,但该过程本质上是递归的。
答案 6 :(得分:0)
递归与非递归之间的区别; 递归实施有点更容易验证的正确性;的非 递归实现有点更高效。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?