通过匹配输入文件中的字符串来编写新文件
我有一些关于使用Python编写脚本的天真问题。
我有一些
形式的输入文件"{1,g,{Frog,12}}",(x**2+.7*x)/2**x
"{2,{g,h},{Pig,17}}",(.8*x**3-1.3*x)/2.5**x
等,其中第一列的第一个和最后一个元素总是整数,第一列的第二个元素可以是字符串或列表,第一列的第三个元素是字符串,第二个元素是第二列column是新变量的函数。
我想创建一个输出文件,它接受每一行并以下列形式写入新文件:
if newstr==1gCow82:
return eval((.2*x**2+x-.3)/1.8**x)
elif newstr==1gFrog12:
return eval((x**2+.7*x)/2**x)
elif newstr==2ghPig17:
return eval((.8*x**3-1.3*x)/2.5**x)
(我将在其中添加类似
的内容 def bignewfunction(a,b,c,d,x):
newstr="".join(str(a),b,c,str(d))
手动地)。
我认为这不应该那么难,但它可能需要一些我无法吸收的正则表达式机制(例如,如何转换字符串“{a1,b1,{c1,d1} “到一个没有引号,括号或逗号的字符串”,还有一些我不知道的Python文件创建。或者,如果我可以从输入文件的第一列中删除括号和引号可能会更容易,但这也需要我目前缺乏的类似脚本技能。
非常感谢任何帮助。提前谢谢!
编辑已修改,以包含输入文件外观的更多具体示例。
1 个答案:
答案 0 :(得分:0)
我不熟悉Python,但有一些带有正则表达式的伪代码可以帮助你解决问题:
prefix = ''
for (find = regexfind(/"((?:[^"\\]|\\.)*)",([^\n]+)/gi)) {
print prefix + 'if newstr==' + find[1].replace("\W", '') + ':'
print ' return eval(' + find[2] + ')'
prefix = 'el'
}
\W(大写!W)捕获不是a-z,0-9或_的所有内容,并用空字符串替换它。
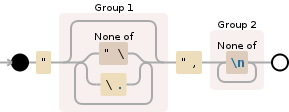
可视化较长的正则表达式,为您提供所需的2个单独的部分:
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?