获得一个后视可以根据需要回顾多少个角色?
我是这个正则表达式:
(\[\[.*?\]\])(?<!".*?)
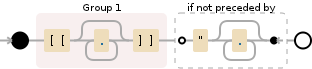
和这个测试数据:
[[Hello]]
<tag Text="my [[Test]] is [[Test2]] for [[Test3]][[Test4]]">
如何让这种后视忽略"前面的那些?
它应与[[Hello]]匹配,但不与剩余部分匹配。但是,它当然与它们相匹配。
2 个答案:
答案 0 :(得分:4)
你的正则表达式实际上是为你的具体输入做的,我会写..(Working Demo)
\[\[[^]]*\]\](?<!"[^"]*)
您也可以考虑在上下文中使用alternation operator,在左侧放置要排除的内容,(说扔掉它,它是垃圾)并放置您想要匹配的内容右侧的捕获组。
然后你可以参考捕获组来获得你的匹配结果。 (Working Demo)
"[^"]*"|(\[\[[^]]*\]\])
答案 1 :(得分:1)
丢弃技术
您可以使用正则表达式技术来丢弃您不想要的内容。它包含一个图案线:
discard1|other discard|more crap|(the content I want)
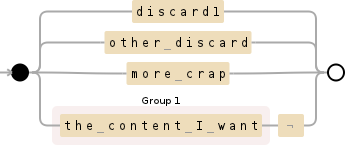
请注意,您想要的内容是最右侧和捕获组内的内容:
说,你可以使用这个正则表达式:
.*".*".*|.*?(\[\[.*?\]\]).*?
<强> Working demo
MATCH 1
1. [0-9] `[[Hello]]`
环视
另一方面,如果你想使用正则表达式的外观(lookbehind和lookahead)你可以使用这个正则表达式:
(?<!").*?(\[\[.*?\]\])(?!.*")
<强> Working demo

但我喜欢丢弃技术,它非常清晰,可以省去很多麻烦。如果您查找zx81,anubhava帖子,他们会在正则表达式上发挥作用,您可以了解很多相关内容。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?