如何使用正则表达式找到所有Markdown链接?
在Markdown中,有两种方法可以放置链接,一种是只输入原始链接,例如:http://example.com,另一种方法是使用()[]语法:(Stack Overflow)[http://example.com ]
我试图编写一个可以匹配这两者的正则表达式,如果它是第二个匹配也可以捕获显示字符串。
到目前为止,我有这个:
(?P<href>http://(?:www\.)?\S+.com)|(?<=\((.*)\)\[)((?P=href))(?=\])
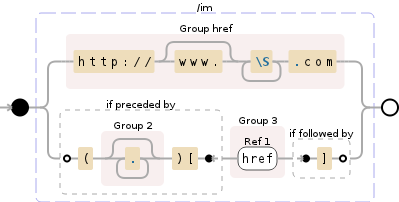
但这似乎与Debuggex中我的两个测试用例中的任何一个都不匹配:
http://example.com
(Example)[http://example.com]
真的不确定为什么第一个至少没有匹配,是否与我对命名组的使用有关?如果可能的话,我希望继续使用,因为这是一个简化的表达式来匹配链接,在真实的例子中,我觉得在同一模式的两个不同的地方复制它太长了。
我做错了什么?或者这根本不可行?
编辑:我在Python中这样做会使用他们的正则表达式引擎。
1 个答案:
答案 0 :(得分:6)
你的模式不起作用的原因在于:(?<=\((.*)\)\[)因为Python的re模块不允许变长长度的后视。
您可以使用the new regex module of Python 以更方便的方式获得所需内容(因为re模块的功能比较少)。
示例:(?|(?<txt>(?<url>(?:ht|f)tps?://\S+(?<=\P{P})))|\(([^)]+)\)\[(\g<url>)\])
模式细节:
(?| # open a branch reset group
# first case there is only the url
(?<txt> # in this case, the text and the url
(?<url> # are the same
(?:ht|f)tps?://\S+(?<=\P{P})
)
)
| # OR
# the (text)[url] format
\( ([^)]+) \) # this group will be named "txt" too
\[ (\g<url>) \] # this one "url"
)
此模式使用分支重置功能(?|...|...|...),允许在交替中保留捕获组名称(或数字)。在模式中,由于?<txt>组在交替的第一个成员中首先打开,因此第二个成员中的第一个组将自动具有相同的名称。 ?<url>组也是如此。
\g<url>是对命名子模式?<url>的引用(就像一个别名,这样就不需要在第二个成员中重写它了。)
(?<=\P{P})检查网址的最后一个字符是否不是标点符号(例如,有助于避免关闭方括号)。 (我不确定语法,可能是\P{Punct})
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?