这更像是一个matlab /数学脑筋急转弯而非一个问题
这是设置。对我正在使用的值没有假设。
n=2; % dimension of vectors x and (square) matrix P
r=2; % number of x vectors and P matrices
x1 = [3;5]
x2 = [9;6]
x = cat(2,x1,x2)
P1 = [6,11;15,-1]
P2 = [2,21;-2,3]
P(:,1)=P1(:)
P(:,2)=P2(:)
modePr = [-.4;16]
TransPr=[5.9,0.1;20.2,-4.8]
pred_modePr = TransPr'*modePr
MixPr = TransPr.*(modePr*(pred_modePr.^(-1))')
x0 = x*MixPr
然后是时候应用以下公式来获得myP
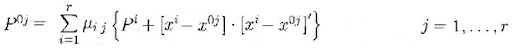
,其中μij是MixPr。我使用此代码来获取它:
myP=zeros(n*n,r);
Ptables(:,:,1)=P1;
Ptables(:,:,2)=P2;
for j=1:r
for i = 1:r;
temp = MixPr(i,j)*(Ptables(:,:,i) + ...
(x(:,i)-x0(:,j))*(x(:,i)-x0(:,j))');
myP(:,j)= myP(:,j) + temp(:);
end
end
有些聪明人提出这个公式作为产生myP
for j=1:r
xk1=x(:,j); PP=xk1*xk1'; PP0(:,j)=PP(:);
xk1=x0(:,j); PP=xk1*xk1'; PP1(:,j)=PP(:);
end
myP = (P+PP0)*MixPr-PP1
我试图制定两种方法之间的相等性,似乎就是这一种。为了简化操作,我在两种方法中都跳过了矩阵P的总和。
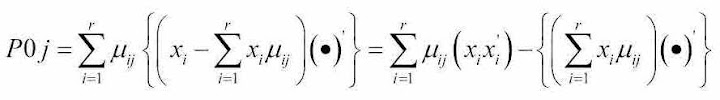
其中第一部分表示我使用的公式,第二部分来自他的代码片段。你认为这是一个明显的平等吗?如果是,请忽略以上所有内容,然后尝试解释原因。我只能从LHS开始,经过一些代数我认为我证明它等于RHS。但是,我不知道他(或她)是如何首先想到它的。
1 个答案:
答案 0 :(得分:1)
使用E作为期望,您的公式的一维版本是熟悉的:
Variance(X) = E((X-E(X))^2) = E(X^2) - E(X)^2
虽然第二种形式可能更容易编程,但由于四舍五入错误,我担心会因使用它而以负面(或多维情况下,非正定)答案结束。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?