有人可以解释正则表达式/(.*)\.(.*)/?
我想用正则表达式在Groovy中获取文件扩展名,比方说South.6987556.Input.csv.cop。
http://www.regexplanet.com/advanced/java/index.html告诉我第二组确实包含cop扩展名。这就是我想要的。
0: [0,27] South.6987556.Input.csv.cop
1: [0,23] South.6987556.Input.csv
2: [24,27] cop
我只是不明白为什么结果不会
0: [0,27] South.6987556.Input.csv.cop
1: [0,23] South
2: [24,27] 6987556.Input.csv.cop
获得此类结果的正则表达式应该是什么?
2 个答案:
答案 0 :(得分:2)
要获得所需的输出,你的正则表达式应该是:
((.*?)\.(.*))
查看DEMO网站右下角的已捕获组。
<强>解释
( group and capture to \1:
( group and capture to \2:
.*? any character except \n (0 or more
times) ? after * makes the regex engine
to does a non-greedy match(shortest possible match).
) end of \2
\. '.'
( group and capture to \3:
.* any character except \n (0 or more
times)
) end of \3
) end of \1
答案 1 :(得分:2)
以下是此正则表达式的可视化
(.*)\.(.*)
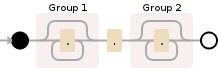
用文字
-
(.*)匹配尽可能大的任何内容并引用它 -
\.匹配一个期间,没有引用(无括号) -
(.*)再次匹配任何内容,可能为空,并引用它
在你的情况下这是
-
(.*):South.6987556.Input.csv -
\.:. -
(.*):cop
它不仅仅是South和6987556.Input.csv.cop,因为第一部分(.*)不是可选的,而是贪婪的,必须后跟句点,因此引擎会尝试匹配最大可能的字符串。
您的预期结果将由此正则表达式创建:(.*?)\.(.*)。量词之后的?(在这种情况下为*)将引擎的行为切换为ungreedy,因此将搜索最小的匹配字符串。默认情况下,大多数正则表达式引擎都是贪心的。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?